async-profiler로 서버의 병목을 추적하다
스택 샘플링 기반 CPU/할당 분석으로 성능 올리기
이전에 Gatling을 사용하여 내가 만들어본 bio 및 nio 서버의 성능 및 안정성 테스트↗를 진행한 바 있다.
그리고 서버의 더 구체적인 구조↗에 대해서도 서술한 바 있다.
오늘은 async-profiler로 더 정확한 원인을 분석하여 성능을 개선해본 회고를 작성해보려고 한다.
주로 테스트한 조합은 nio + VT 이다. 이 조합이 가장 전체적으로 성능 저하를 보였기 때문에 골랐다.
async-profiler 분석
지금처럼 “Warm-up 후엔 정상인데, 초반에만 실패 집중” 패턴이 나올 때는 단순 로깅으로는 한계가 있고, 프로파일러나 이벤트 트레이싱 기반의 샘플링 분석이 필요하다고 생각했다.
우선은 샘플링 프로파일러로 전체 흐름 파악해보자.
목표는 CPU time과 wall time의 차이를 보는 것이다. “무엇이 오래 걸렸는가”보다 “어디서 대기했는가”를 찾아야 병목지점을 찾을 수 있다.
다음과 같은 간단한 스크립트를 작성하여 분석을 진행했다.
#!/bin/bash # Sprout 서버 부하테스트 + Async Profiler 통합 스크립트 (CPU / Alloc / Wall) SERVER_PORT=8080 DURATION=30 ASYNC_PROFILER_HOME=/Users/mac/IdeaProjects/async-profiler/build SIMULATION_CLASS=benchmark.HelloWorldSimulation PID=$(lsof -i :$SERVER_PORT -t) if [ -z "$PID" ]; then echo "서버가 실행 중이 아닙니다. 먼저 Sprout 서버를 실행하세요." exit 1 fi echo "Sprout 서버 PID = $PID" ASPROF="$ASYNC_PROFILER_HOME/bin/asprof" if [ ! -f "$ASPROF" ]; then echo "asprof 실행 파일을 찾을 수 없습니다. 경로를 확인하세요." exit 1 fi echo "1) Gatling 부하테스트 시작..." ./gradlew gatlingRun --simulation=$SIMULATION_CLASS & GATLING_PID=$! sleep 3 echo "2) Async Profiler로 $DURATION초간 프로파일링..." # CPU env DYLD_LIBRARY_PATH=$ASYNC_PROFILER_HOME/lib $ASPROF \ -d $DURATION -e cpu -o flamegraph -f cpu-flamegraph.html $PID # Allocation env DYLD_LIBRARY_PATH=$ASYNC_PROFILER_HOME/lib $ASPROF \ -d $DURATION -e alloc -o flamegraph -f alloc-flamegraph.html $PID # Wall-clock env DYLD_LIBRARY_PATH=$ASYNC_PROFILER_HOME/lib $ASPROF \ -d $DURATION -e wall -o flamegraph -f wall-flamegraph.html $PID wait $GATLING_PID echo "" echo "프로파일링 완료!" echo "생성된 결과 파일:" echo " - cpu-flamegraph.html (CPU 사용 분석)" echo " - alloc-flamegraph.html (힙 메모리 할당 분석)" echo " - wall-flamegraph.html (실제 wall-clock 병목 분석)" echo "" open cpu-flamegraph.html open alloc-flamegraph.html open wall-flamegraph.html
프로파일링한 부분은 초반 30초 정도고, 해당 부하테스트는 1분 30초 ~ 2분 정도 소요된다. 초기에 많은 실패가 있으므로 해당 부분에서 병목이 반드시 보일것이라 생각했다.
이때 사용한 부하테스트는 "Hello World!"를 반환하는 부하테스트로 다음과 같다.
package benchmark; import io.gatling.javaapi.core.*; import io.gatling.javaapi.http.*; import static io.gatling.javaapi.core.CoreDsl.*; import static io.gatling.javaapi.http.HttpDsl.*; import java.time.Duration; public class HelloWorldSimulation extends Simulation { HttpProtocolBuilder httpProtocol = http .baseUrl("http://localhost:8080") .acceptHeader("text/plain,application/json") .userAgentHeader("Gatling Performance Test") .shareConnections() // 커넥션 재사용 .disableFollowRedirect() .disableWarmUp() // Gatling 기본 warm-up 비활성화 .maxConnectionsPerHost(200) .connectionHeader("keep-alive") .header("Keep-Alive", "timeout=5, max=1000"); // Warm-up 시나리오 // 목적: 서버 및 JVM JIT, 스레드풀, 소켓 풀 예열 ScenarioBuilder warmUp = scenario("Warm-up Phase") .exec( http("Warm-up request") .get("/benchmark/hello") .check(status().is(200)) ); // 본격 부하 시나리오 ScenarioBuilder loadTest = scenario("Hello World Load Test") .exec( http("GET /benchmark/hello") .get("/benchmark/hello") .check(status().is(200)) ); { setUp( // Warm-up 단계: 낮은 부하로 10초간 서버를 예열 warmUp.injectOpen( rampUsers(5).during(Duration.ofSeconds(5)), constantUsersPerSec(10).during(Duration.ofSeconds(10)) ).protocols(httpProtocol), // 본 테스트 단계: warm-up 후 바로 실행 loadTest.injectOpen( nothingFor(Duration.ofSeconds(15)), // warm-up 이후 실행 rampUsers(10).during(Duration.ofSeconds(5)), rampUsers(50).during(Duration.ofSeconds(10)), constantUsersPerSec(100).during(Duration.ofSeconds(30)), rampUsersPerSec(100).to(200).during(Duration.ofSeconds(10)), constantUsersPerSec(200).during(Duration.ofSeconds(20)) ).protocols(httpProtocol) ) .assertions( global().responseTime().max().lt(1000), global().successfulRequests().percent().gt(99.0) ); } }
package app.benchmark; import sprout.beans.annotation.Controller; import sprout.mvc.annotation.GetMapping; import sprout.mvc.annotation.RequestMapping; @Controller @RequestMapping("/benchmark") public class BenchmarkController { @GetMapping("/hello") public String hello() { return "Hello, World!"; } }
개선전 분석 결과
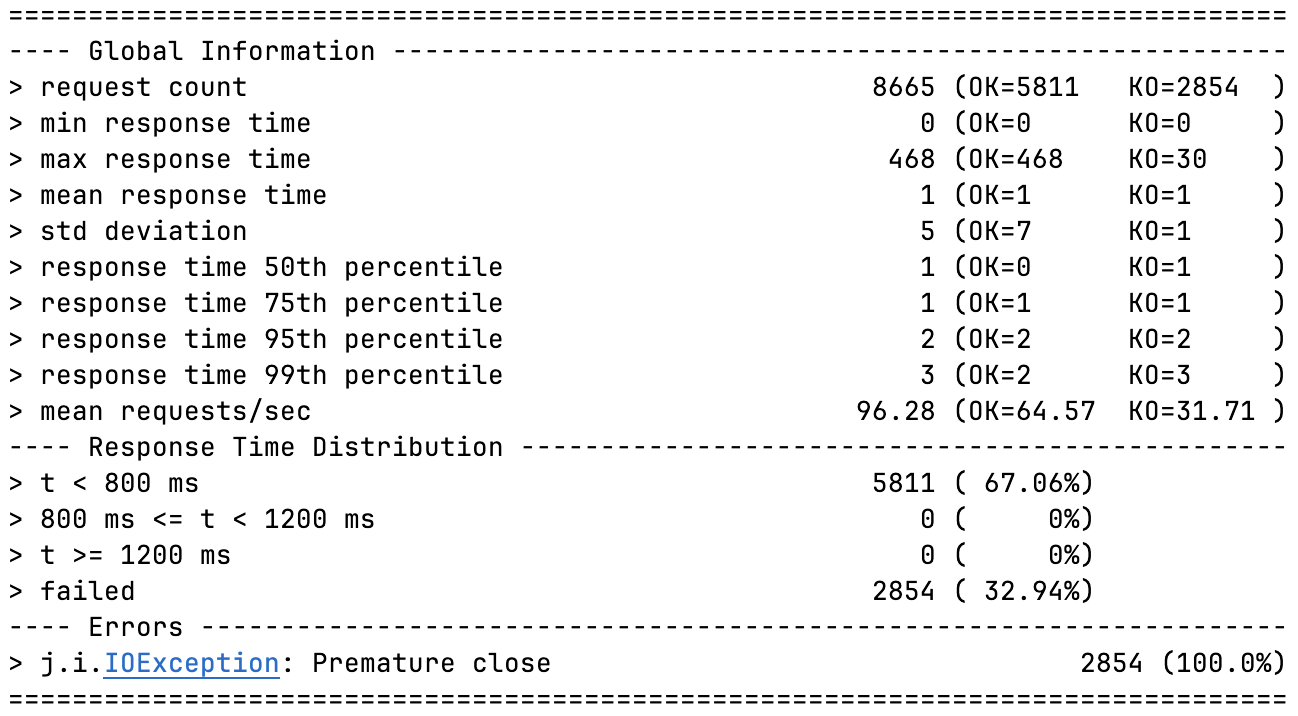
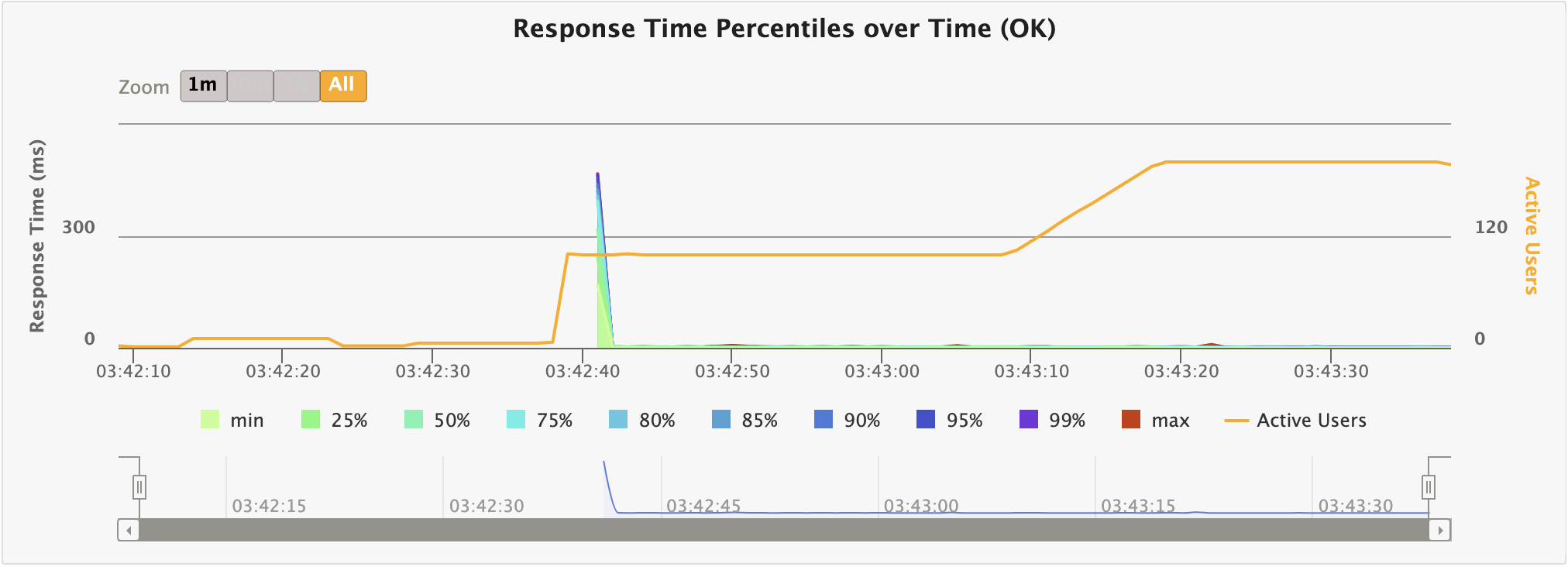
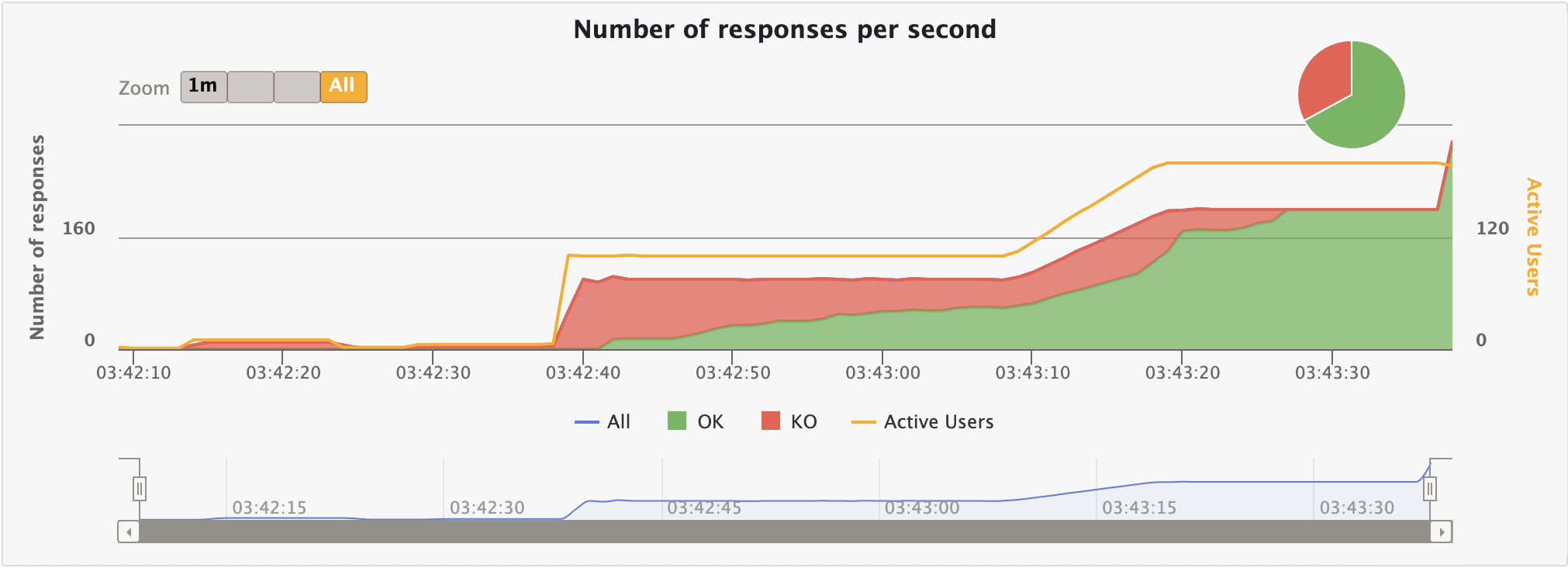
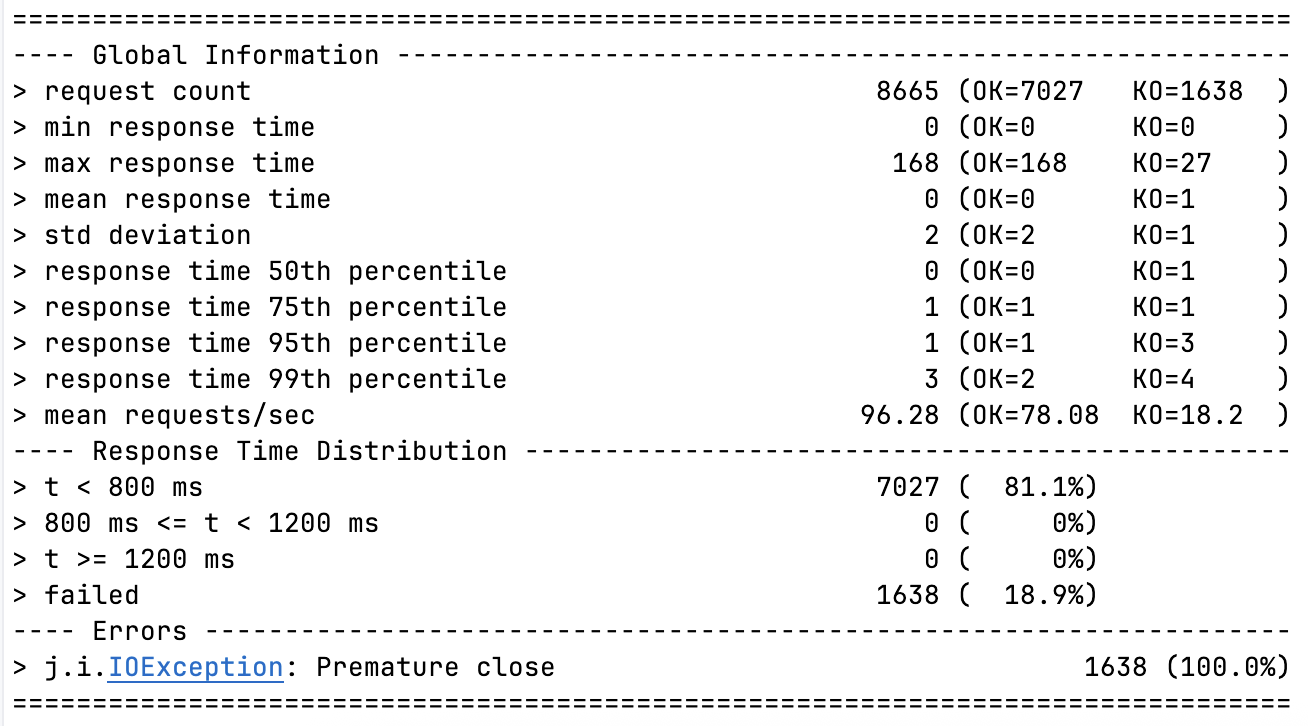
지연 시간엔 큰 무리는 없지만 그래프에서 확인할 수 있다시피 초반 KO가 극심하다.
이는 기존 성능 테스트 글에서도 자세히 살펴본 바 있으니 넘어가겠다.
warm up 구간 실패율에 대한 예측
이전에 작성한 글에서 다음과 같은 실패율에 대한 예측을 해두었었다.
의심되는 원인들
-
스레드 지연 생성 문제
- Platform Threads (RequestExecutorPoolService, pool size 150): 고정 풀 크기라 초반에 풀을 채우는 데 시간이 걸린다. 만약 풀 사이즈가 작거나, 초기화되지 않은 상태에서 ramp-up이 오면 대기 큐가 쌓여 KO 발생할 수밖에 없다. Hybrid + Platform은 BIO의 단순함 덕에 괜찮지만, NIO + Platform은 Selector와 결합되어 더 느려진다.
- Virtual Threads (VirtualRequestExecutorService): Java 21+에서 가볍지만, 초반에 많은 virtual threads를 생성할 때 JVM의 Loom 구현 비용(스레드 carrier 초기화)이 발생한다. 하지만 platform보다 훨씬 scalable해서 Hybrid + Virtual이 가장 빠른 안정화를 보이는는 것 아닐까 추측.. NIO + Virtual이 느린 건 NIO의 비동기가 virtual threads의 이점을 초반에 상쇄하기 때문이다. virtual threads는 blocking 코드(BIO)에 더 잘 맞는다. (실제로 netty 팀에서도 nio와 가상스레드 조합을 비추천하기도 하였다.)
아니면 Gatling의 constantUsersPerSec(10) warm-up이 너무 약해서 풀/threads가 제대로 예열되지 않는 것일수도 있다. warm-up을 더 길게 (e.g., 30초) 하거나 users를 점진적으로 늘려보는게 해법이 될 수도 있음. Gatling의 자체 웜업도 일부러 배제했는데, 이러한 현상을 전부 확인해보고 싶어서 였긴 하다.
-
JIT 최적화까지 시간이 걸리는 점
- Java의 HotSpot JVM은 코드가 여러 번 실행된 후에 JIT (Just-In-Time) 컴파일을 한다. 초반에는 interpreted mode로 느리고, 메서드 호출 횟수가 쌓일수록 optimized native code로 전환된다.
- 왜 NIO가 더 느릴까?: NIO (NioHttpProtocolHandler)는 Selector, Channel, ByteBuffer 같은 복잡한 루프가 있어서 JIT threshold에 도달하는 데 더 많은 반복이 필요하다. BIO (BioHttpProtocolHandler)는 단순 socket read/write라 빨리 최적화될 수 있다. 그래프에서 특정 시점부터 OK가 급증하는 건 JIT이 "뜨거워진" 시점을 의미한다.
찾아본 해결 방안으로는 서버 로그에 -XX:+PrintCompilation 플래그를 추가해 JIT 로그를 보면 초반 컴파일이 부족한 걸 확인하여, warm-up을 늘리거나, JMH 같은 microbenchmark로 미리 JIT을 trigger 해볼 수 있다고 한다.
-
TCP backlog (대기 큐) 포화
서버의 listen backlog (e.g., ServerSocket backlog 파라미터, default 50)이 작으면 연결이 쌓일 때 SYN queue가 overflow되어 연결이 거부된다. (KO 발생) Gatling의 rampUsers(10).during(5s)처럼 급 부하가 오면 더 심할 것이다. NIO 영향: NIO에서 Selector가 준비되지 않은 상태에서 연결이 몰리면 backlog이 빨리 포화된다. Hybrid (BIO)는 각 연결에 즉시 thread를 할당하니 상대적으로 덜 민감할 수밖에 없을 것이다.
OS 수준에서 net.core.somaxconn (Linux default 128)을 확인하고 늘려볼 수 있긴하다. 혹은 서버 코드에서 ServerSocket 생성 시 backlog을 크게 설정하는 것이 방법이 될 수도 있다.
-
NIO에서 Selector 준비시간과 첫 select() blocking 문제
- 이게 핵심 병목 지점이다. NioHttpProtocolHandler에서 Selector.open()과 channel.register()가 초반 비용을 높게 가져간다. 첫 select() 호출은 blocking 될 수 있어서 (no events ready) 지연이 발생. 특히 Virtual Threads와 결합 시, selector wakeup/park 비용이 추가된다.
- 왜 NIO + Virtual이 가장 느릴까?: Virtual threads는 blocking을 피하려 하지만, NIO의 이벤트 드리븐 모델이 초반에 events를 쌓아두다 한 번에 처리하려 하니 지연되는 것이다. Hybrid + Virtual은 BIO의 즉시 처리 덕에 빠를 수 있다.
서버 로그에 Selector 관련 타이밍을 로깅하거나, jstack과 같은 툴로 초반 thread dump를 봐서 blocking 확인해야 구체적 원인을 파악할 수 있을 것 같다.
내가 예측했던 부분들이 정말 원인인지도 살펴보자.
async-profiler CPU profile
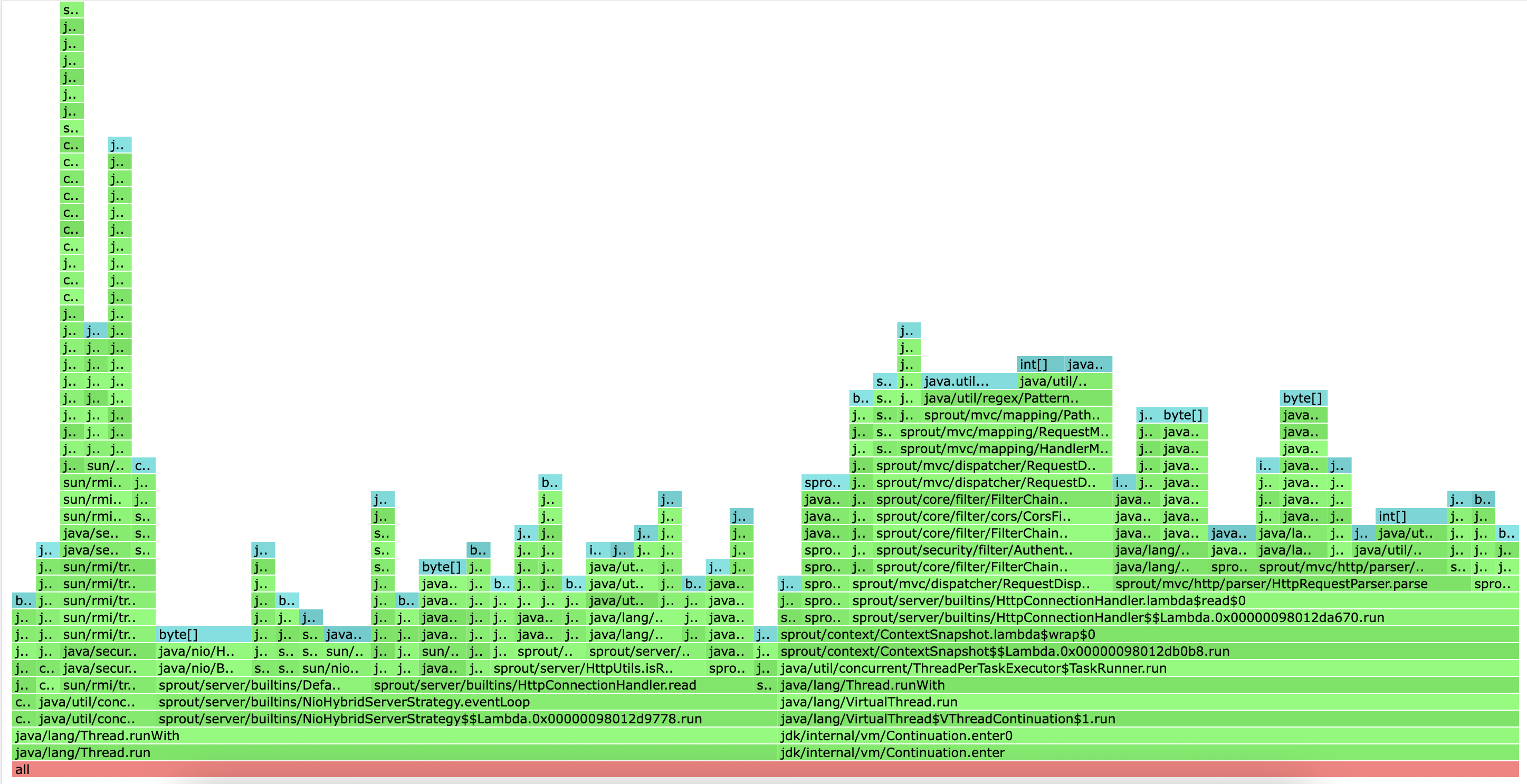
async-profilerCPU profile는 스택 트레이스를 샘플링하여 CPU를 많이 사용하는 코드를 시각적으로 보여주는 도구입니다. 그래프의 각 막대는 함수를 나타내며, 막대의 너비가 넓을수록 해당 함수가 CPU를 더 많이 사용했음을 의미합니다.
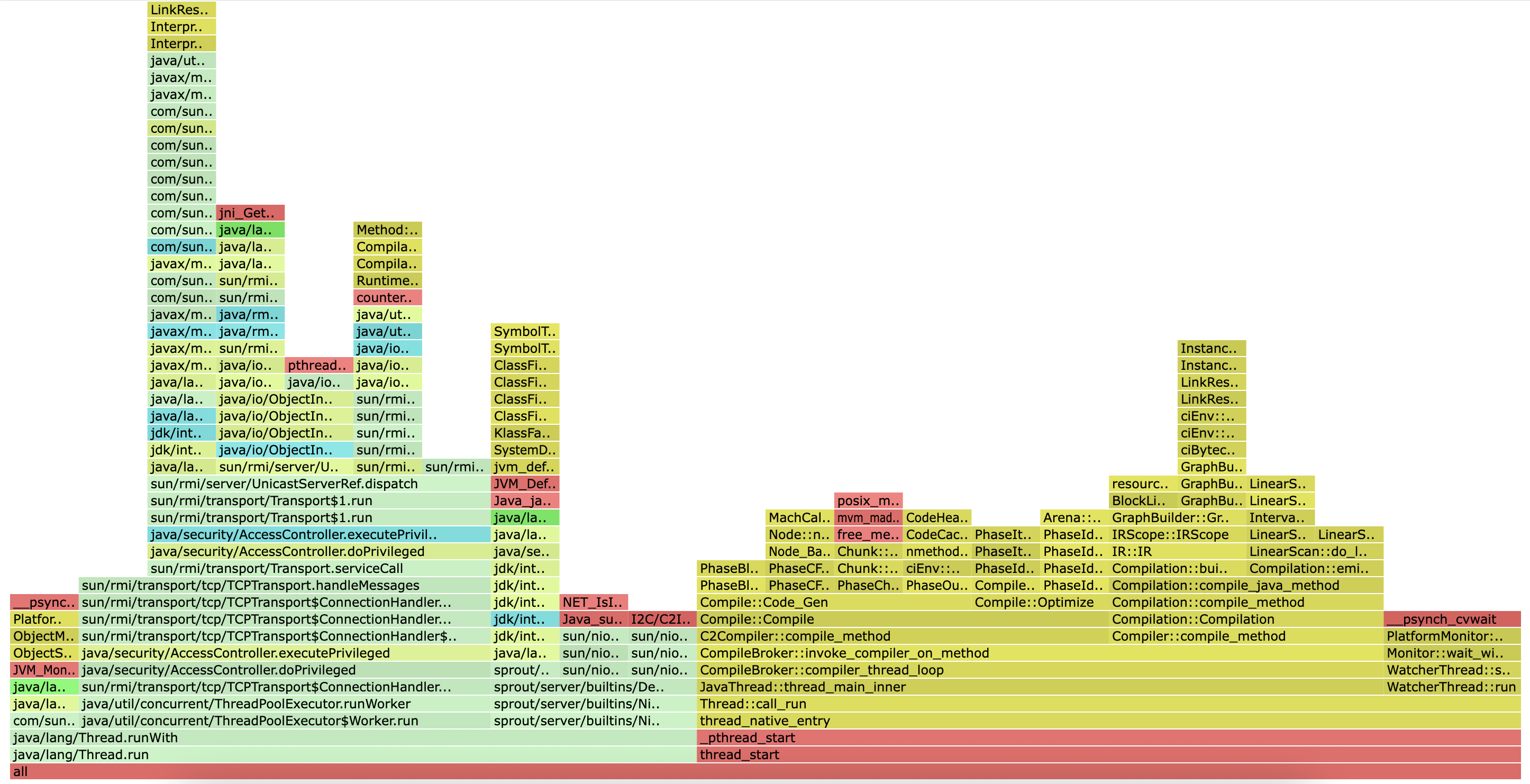 이 위의 스택이 CPU를 점유한 실제 코드를 보여주고 있다.
이 위의 스택이 CPU를 점유한 실제 코드를 보여주고 있다.
플레임그래프에서 아래쪽(thread_start, _pthread_start, _start)은 항상 “스레드의 진입점”을 나타낸다.
그래서 thread_start는 “CPU 샘플들이 여러 워커 스레드의 실행 시점에 있었음”을 보여주고 있다.
주요 분석 결과
JIT 컴파일 (JIT Compilation)
- 가장 많은 CPU 시간을 소비하는 부분 중 하나는 Java의 JIT 컴파일러이다.
- 스택 트레이스에서 C2Compiler::compile_method, compiler_thread_loop, CodeCache::allocate 와 같은 함수들이 많이 나타나고 있다.
- 이는 애플리케이션이 실행되면서 Java 바이트코드를 네이티브 코드로 컴파일하는 데 많은 CPU를 사용하고 있음을 의미한다.
JMX (Java Management Extensions)
- DefaultMBeanServerInterceptor.getAttribute 와 관련된 JMX 호출이 상당한 CPU를 사용하고 있다.
- 이는 JMX를 통해 애플리케이션의 상태를 모니터링하는 과정에서 부하가 발생하고 있음을 시사한다. 어떤 속성(attribute)을 조회하는지, 그리고 얼마나 자주 조회하는지 확인해 볼 필요가 있어보인다.
네트워크 연결 수락 (Connection Accepting)
DefaultConnectionManager.acceptConnection함수가 포함된 스택이 넓게 나타난다.- 하지만 이 스택의 하위 함수로는
__psynch_cvwait와 같은 대기(wait) 관련 함수가 보인다. CPU 프로파일에서 대기 함수가 나타나는 것은 스레드가 CPU를 사용하면서도 실제로는 다른 리소스를 기다리며 대기(spin-wait)하고 있을 가능성을 뜻한다. 연결 수락 로직에 경합(contention)이 발생하거나 비효율적인 부분이 있는지 확인해 볼 필요가 있어보인다.
기타 대기 상태
Object.wait와 같은 명시적인 대기 호출도 CPU 프로파일에 나타나고 있다. 이는 TCP 연결 핸들러와 스레드 풀 워커에서 발생하며, 위와 마찬가지로 I/O 대기 중 스레드가 완전히 휴면 상태에 들어가지 않고 CPU를 일부 소모하는 상황일 수 있다.
async-profiler Allocation profile
이 그래프는 어떤 코드 경로에서 메모리 할당이 많이 발생하는지를 보여줍니다. 여기서 막대의 너비는 해당 함수와 그 하위 함수들이 할당한 총 메모리 양에 비례합니다. 그래서 넓은 막대는 메모리를 많이 사용하는 지점을 의미합니다.
메모리 할당 프로파일링 결과(alloc-flamegraph.html)를 분석해보자.
주요 분석 결과
HTTP 요청 파싱 (Request Parsing)
- 가장 큰 메모리 할당을 유발하는 곳 중 하나는
HttpHeaderParser.parse메서드다. 이 메서드는 HTTP 요청을 읽고 파싱하는 과정에서ByteBuffer.allocate를 통해 많은HeapByteBuffer객체를 생성하고 있다. - 이는 매 요청마다 헤더와 바디를 읽기 위한 버퍼를 새로 할당하기 때문에 발생하는 것으로, 트래픽이 많아질수록 이 부분이 메모리 사용량과 GC(Garbage Collection) 부하의 주된 원인이 될 수 있다.
요청 라우팅 및 필터링 (Request Routing & Filtering)
FilterChain.doFilter를 시작으로 하는 요청 처리 파이프라인에서 상당한 메모리 할당이 발생하고 있다.- 특히
HandlerMappingImpl.findHandler(요청을 처리할 컨트롤러를 찾는 과정)와AntPathRequestMatcher.matches(URL 경로를 비교하는 과정) 메서드가 눈에 띈다. - 이는 요청 URL을 특정 패턴과 매칭시키기 위해 정규식(
Regex) 관련 객체(Pattern,Matcher)나 임시 문자열 객체들이 내부적으로 생성되기 때문이다.
HTTP 응답 버퍼 생성 (Response Buffer Creation)
HttpUtils.createResponseBuffer함수 역시 주요 메모리 할당 지점이다. 클라이언트에게 보낼 응답 데이터를 담을 버퍼를 생성하는 역할을 하며, 이 과정에서 많은 메모리를 할당하고 있다.- 또한, 이 스택에서는
ObjectOutputStream관련 호출도 보이는데, 이는 객체 직렬화(Serialization) 과정에서 추가적인 메모리 할당이 발생하고 있음을 시사하고 있다.
기타 일반적인 할당
- 그 외에도 스레드 실행(
Thread.run), 문자열 처리(String.toLowerCase,StringBuilder.append), 컬렉션(ArrayList,HashMap) 사용 등 애플리케이션 전반에서 발생하는 자잘한 객체 생성이 모여 전체 메모리 사용량에 기여하고 있다.
메모리 할당 분석에서는 코드 개선점을 꽤 찾았다.
async-profiler wall-clock profile
이 프로파일은 이전의 CPU, 메모리 프로파일과 성격이 다릅니다.
- CPU 프로파일: 스레드가 'CPU 위에서' 실행 중일 때만 샘플링합니다.
- Wall-Clock 프로파일: 스레드의 상태와 관계없이(CPU 사용, I/O 대기, 잠금(Lock) 대기, 휴면(Sleep) 등) 실제 경과 시간을 기준으로 샘플링합니다.
따라서 Wall-Clock 프로파일은 CPU 사용뿐만 아니라, 무엇을 기다리느라 시간이 소요되는지(예: I/O, 락 경합)를 파악하는 데 매우 유용합니다.
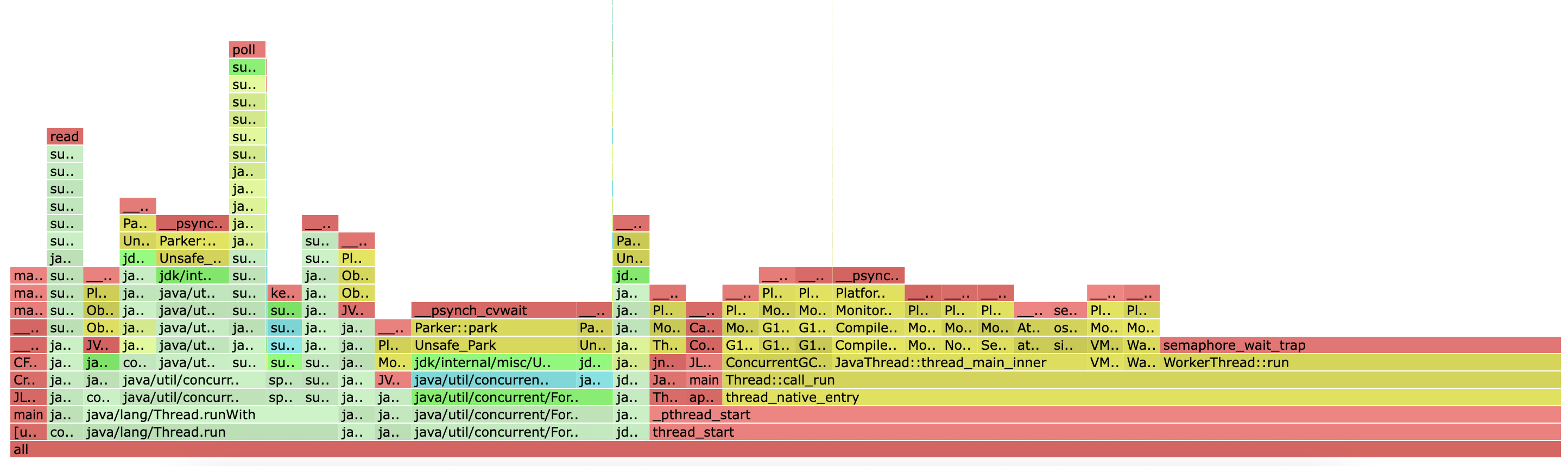

주요 분석 결과
프로파일을 분석한 결과, 애플리케이션의 전체 실행 시간 중 압도적인 부분(95% 이상)이 스레드의 대기(Waiting) 또는 휴면(Idle) 상태에서 소요된 것으로 나타났다.
세마포어 대기 (semaphore_wait_trap)
- 가장 넓은 스택(전체의 약 54%)은
semaphore_wait_trap에서 발생한다. - 이 대기는 주로 JVM의 내부 스레드들, 예를 들어 JIT 컴파일러 스레드(
CompilerThread)나 G1 GC 관련 스레드(G1ConcurrentMarkThread)가 다음 작업을 기다리며 휴면 상태에 있을 때 발생한다. 고로, 이는 해당 스레드들이 항상 실행되는 것이 아니라, 필요할 때만 동작하기 때문에 지극히 정상적인 상태라고 한다.
파킹 상태 (LockSupport.park)
- 두 번째로 넓은 스택(전체의 약 26%)은
LockSupport.park함수에서소요 되었다. - 이는 주로 스레드 풀(Thread Pool)의 워커 스레드(
WorkerThread)가 처리할 작업이 없어 쉬고 있는 상태를 의미한다. 애플리케이션에 들어오는 요청이 없거나 적을 때 스레드 풀의 스레드들은 대부분 이 상태에 있게 된다.
객체 대기 (Object.wait)
- 세 번째로,
Reference Handler나Finalizer와 같은 JVM의 내부 스레드가Object.wait상태에서 시간을 보내고 있다. (전체의 약 16%) - 이 스레드들은 처리해야 할
Reference객체(예:SoftReference,WeakReference등)나 finalize가 필요한 객체가 큐에 들어올 때까지 대기하며, 이 역시 정상적인 동작이라고 한다.
종합 결론
지금까지 분석한 CPU, 메모리 할당, Wall-Clock 프로파일을 종합하여 애플리케이션의 전반적인 성능 특성을 파악할 수 있었다.
우선 애플리케이션은 CPU 병목 상태가 아니다.
Wall-Clock 프로파일에서 확인 가능하듯, 애플리케이션은 대부분 외부 요청이나 작업을 대기하며 지냈다..
작업시의 병목지점은 명확하다
CPU 사용 CPU 프로파일링 결과 작업이 활발할 때엔 CPU는 주로 JIT 컴파일과 JMX 모니터링에 사용되었다 메모리 사용 작업이 활발할 때 메모리는 주로 HTTP 요청 파싱, 라우팅, 응답 버퍼 생성 과정에서 집중적으로 할당되었다.
개선해야 할 부분
- 만약 성능 개선의 목표가 처리량 향상이라면, CPU 및 메모리 프로파일에서 확인했던 HTTP 요청 처리 파이프라인의 비효율적인 부분을 개선하는데에 집중해야 한다. (버퍼를 재사용한다거나, 라우팅 로직 최적화 등)
- 만약 성능 개선의 목표가 리소스 사용량 감소라면, 현재 워크로드에 비해 스레드 풀의 유휴 스레드가 너무 많지는 않은지 검토하여 풀 크기를 조절해볼 수 있을 것 같다.
Warm-up 병목의 명확한 원인
이는 내가 이전에 예측했던 대로 JVM의 JIT 컴파일이다 여러가지 데이터를 종합해서 생각했을 때 다음과 같은 시나리오로 발생한 것이다.
-
차가운 상태(Cold State): 부하 테스트가 시작되면 첫 요청들이 서버에 도달한다. 이때의 서버 코드는 최적화되지 않은 '차가운' 상태이다.
-
JIT 컴파일러의 개입: JVM은 요청을 처리하는 코드(HTTP 파싱, 라우팅 등)가 뜨겁다고 판단하고 이를 네이티브 코드로 컴파일하여 최적화를 시작한다. CPU 프로파일에서
C2Compiler::compile_method이 높게 나타난게 이 증거라고 볼 수 있다. -
CPU 리소스 경합: JIT 컴파일은 매우 CPU 집약적인 작업이다. 이로 인해 CPU 자원이 JIT 컴파일에 대거 할당되며 정작 들어오는 요청을 처리할 CPU가 부족해진다.
-
요청 처리 지연 및 실패: 이러한 CPU 경합으로 인해 요청 처리가 지연되고, 서버의 큐가 가득차거나 타임아웃이 발생한다. 그래서 결국 응답을 완료할 수 없게 되고 연결을 조기에 끊어버린다. 이게 Gatling 리포트에 나타난 수많은
j.i.IOException: Premature close에러의 원인이다. -
안정화 상태(Warm State): JIT 컴파일이 완료되면, 코드는 네이티브 수준으로 빠르게 실행된다. 더 이상 컴파일에 CPU를 뺏기지 않기때문에 서버가 온전히 요청 처리에 집중 가능해진다. 그 결과 Gatling 리포트 호분부처럼 에러가 사라지고 응답 시간이 1~3ms 수준으로 급격하게 안정화 되는 것이다.
지금 사용하고 있는 조합인 VT는 I/O 대기 시간을 줄이는데에는 훌륭하지만, JIT 컴파일로 인한 CPU 병목 자체를 해결할 수는 없다. 각 가상스레드가 실행될 때마다 컴파일안 된 코드를 만나면 당연히 똑같이 JIT 컴파일을 유발하기 때문이다.
Warm-up 시간 단축을 위한 해결 방안
1. 가장 현실적인 방법 : 애플리케이션 예열
가장 먼저 시도해볼만한.. 가장 쉬운 방법이기도 하다. 실제 부하 테스트 이전에 서버가 최적화 될 수 있도록 미리 '예열'하는 과정을 추가하는 것이다.
방법
- 부하 테스트 시나리오와 유사한 요청(또는 가장 핵심적인 API 요청)을 보내는 간단한 예열 시나리오 작성
- Gatling 테스트 스크립트의 시작 부분에서, 이 예열 시나리오를 통해 수백~수천(ㅋㅋ, 데이터 상 이 정도는 필요할 것 같다.. 사실 이 이상 필요할 것 같다)의 요청을 미리 보낸다.
- 이 과정에서 JIT 컴파일, 클래스 로딩, 메모리 할당 등이 미리 발생하도록 유도
- 예열이 끝난 후, 통계 측정을 시작하고 본 부하 테스트를 진행
기대 효과 실제 측정 대상인 부하 테스트에서는 이미 코드가 최적화된 상태이므로, 초반 요청 실패 없이 안정적인 성능을 바로 확인할 수 있을 것이다.
2. 더 근본적인 해결책 : AOT 컴파일
JIT 컴파일 자체를 없애고 싶다면 AOT(Ahead-of-Time) 컴파일이 해답이다. GraalVM Native Image는 Java 애플리케이션을 실행 시점(Runtime)이 아닌, 빌드 시점에 네이티브 실행 파일로 미리 컴파일하는 기술이다.
장점
- JIT 컴파일이 없으므로 Warm-up이 거의 사라진다. 시작 즉시 최대 성능을 발휘할 수 있다.
- JVM 없이 실행되므로 메모리 사용량이 매우 적고 시작 속도가 빠르다.
단점
- Reflection, Dynamic Proxy 등 동적인 기능 사용에 제약이 있어 별도 설정이 필요하다.
- 빌드 과정이 복잡하다.
장기적으로 최고의 시작 성능을 원한다면 GraalVM 도입을 검토해 볼만 하기도 하다. 별도 설정도 하기 싫으면 리플렉션 싹 걷어내고 APT로 다시 로직 짜면 됨 ㅋㅋㅋㅋ 해당 장점을 누리기 위해 많은 애플리케이션이 AOT로 옮겨가고 있긴하다. 실제로 스프링도 6버전에서 AOT 지원을 예고 했고, 쿼커스나 마이크로넛 등은 리플렉션없이 프레임워크를 재설계 했음..
3. 절충안 : JIT 컴파일러 튜닝
JVM 옵션을 통해 JIT 컴파일 동작을 조절하여 Warm-up 속도와 최대 성능 사이의 균형을 노려볼 수 있다.
방법: 극단적이지만, JVM 시작 옵션에 -XX:TieredStopAtLevel=1를 추가
효과: 이 옵션은 JVM이 최종 단계의 고도로 최적화된 C2 컴파일을 생략하고, 더 빠른 C1 컴파일만 사용하도록 강제한다. Warm-up은 매우 빨라지지만, 안정화상태의 최대 성능은 C2 컴파일을 사용했을 때보다 다소 낮다.
용도: JIT가 병목의 원인인지 빠르게 확인해보거나, 최대 성능보다 빠른 시작속도가 더 중요한 서비스에 적합한 절충안이라고 볼 수 있다.
하지만 내키지 않는다. Java의 압도적 장점인 처리량을 누릴 수 없는 옵션이라서..(C2 컴파일러가 만든 네이티브 코드는 진짜 좋음.. 런타임에 직접 확인하고 개선하는 거라서 걍 미리 컴파일한 것보다 좋음..) GraalVM 리포트에선, 유료 버전이 아닌 경우엔 처리량이 JIT 컴파일러가 더 좋기 때문이다. 유료(엔터프라이즈)는 그랄이 더 좋다고 발표되긴 함.
개선
일단 내가 지금 JVM 튜닝을 제외하고 당장 해볼법한건 MVC 모듈의 비효율성을 개선하는 것이다. 실제로 로직을 보니
// 전체 응답 버퍼 생성 (헤더 + 바디) ByteBuffer buffer = ByteBuffer.allocate(headerBytes.length + bodyBytes.length); buffer.put(headerBytes); buffer.put(bodyBytes); buffer.flip(); return buffer;
이러하게 사용중이었음. 그리고 연결에서 더 많은 문제가 생기는 이유가, HTTP 메세지를 "조금" 읽은 후에(이때도 버퍼할당), 해당 프로토콜을 판단하고? 해당하는 핸들러로 매핑을 해주는데, 해당 핸들러에서 다시 요청을 확인하기 위해 또 다시 버퍼를 할당.. 마지막으로 응답을 내려줄때? 또다시 버퍼 할당 ㅋㅋㅋ
코드를 그지같이 쓰면 왜 문제가 생기는지 깨닫게 되었다.
이러한 문제를 해결하기 위한 방법도 사실 이미 제시된 바가 많다. 스레드나 데이터커넥션 같이 생성에 비용이 큰 경우는? 풀을 만들어 사용하게 한다. JAVA의 String 도 풀이 있다. 그런 개념으로 버퍼 풀을 만들어 해당 객체를 사용하도록 개선하면 되는 것이다.
이를 위해 실제로 바이트 버퍼 풀을 만들었다. 구현은 다음과 같다. (모니터링 등 부가 기능은 좀 빼고 첨부했습니다. 너무 길어서)
package sprout.server; import sprout.beans.InfrastructureBean; import sprout.beans.annotation.Component; import java.nio.ByteBuffer; import java.util.concurrent.ConcurrentHashMap; import java.util.concurrent.ConcurrentLinkedQueue; import java.util.concurrent.atomic.AtomicLong; @Component public class ByteBufferPool implements InfrastructureBean { /** * 내부 버퍼 풀 구성 정보 클래스. * 각 PoolConfig 인스턴스는 특정 버퍼 크기 그룹을 관리함. */ private static class PoolConfig { final int bufferSize; // 버퍼 크기 final int maxPoolSize; // 풀 내 최대 버퍼 개수 final ConcurrentLinkedQueue<ByteBuffer> pool; // 버퍼 저장소 // 통계 수집용 카운터 (모니터링 및 튜닝에 활용) final AtomicLong acquireCount = new AtomicLong(0); // 요청 횟수 final AtomicLong releaseCount = new AtomicLong(0); // 반환 횟수 final AtomicLong allocateCount = new AtomicLong(0); // 새로 할당된 버퍼 수 PoolConfig(int bufferSize, int maxPoolSize) { this.bufferSize = bufferSize; this.maxPoolSize = maxPoolSize; this.pool = new ConcurrentLinkedQueue<>(); } } // 자주 쓰이는 버퍼 크기 사전 정의 public static final int SMALL_BUFFER_SIZE = 2048; // 2KB → 프로토콜 탐지용 public static final int MEDIUM_BUFFER_SIZE = 8192; // 8KB → 일반 요청 읽기용 public static final int LARGE_BUFFER_SIZE = 32768; // 32KB → 대용량 응답용 private static final int DEFAULT_MAX_POOL_SIZE = 500; private final ConcurrentHashMap<Integer, PoolConfig> pools; // 크기별 풀 저장소 private final boolean useDirect; // Direct ByteBuffer 사용 여부 (네이티브 메모리) public ByteBufferPool() { this(false); } public ByteBufferPool(boolean useDirect) { this.useDirect = useDirect; this.pools = new ConcurrentHashMap<>(); // 기본 풀 초기화 initializePool(SMALL_BUFFER_SIZE, DEFAULT_MAX_POOL_SIZE); initializePool(MEDIUM_BUFFER_SIZE, DEFAULT_MAX_POOL_SIZE); initializePool(LARGE_BUFFER_SIZE, DEFAULT_MAX_POOL_SIZE / 5); // 큰 버퍼는 수 제한 } /** * 특정 버퍼 크기에 대한 새 풀을 초기화. */ public void initializePool(int bufferSize, int maxPoolSize) { pools.put(bufferSize, new PoolConfig(bufferSize, maxPoolSize)); } /** * 풀에서 ByteBuffer를 하나 가져오거나, 없으면 새로 할당. */ public ByteBuffer acquire(int size) { int poolSize = findPoolSize(size); PoolConfig config = pools.get(poolSize); // 관리 대상이 아닌 크기 → 풀링하지 않고 즉시 할당 if (config == null) return allocateBuffer(size); config.acquireCount.incrementAndGet(); // 풀에서 버퍼 하나 꺼내오기 ByteBuffer buffer = config.pool.poll(); if (buffer != null) { buffer.clear(); return buffer; } // 풀 비었을 시 새 버퍼 할당 config.allocateCount.incrementAndGet(); return allocateBuffer(poolSize); } /** * 사용 완료된 버퍼를 해당 풀로 반환. * 풀 크기를 초과하면 버퍼는 GC 대상이 됨. */ public void release(ByteBuffer buffer) { if (buffer == null) return; PoolConfig config = pools.get(buffer.capacity()); if (config == null) return; // 관리 대상 크기가 아니면 무시 config.releaseCount.incrementAndGet(); // 풀 가득 찼으면 버퍼 폐기 if (config.pool.size() >= config.maxPoolSize) return; buffer.clear(); config.pool.offer(buffer); } /** * 요청된 크기에 가장 근접한 풀 크기 찾기. */ private int findPoolSize(int requestedSize) { if (requestedSize <= SMALL_BUFFER_SIZE) return SMALL_BUFFER_SIZE; if (requestedSize <= MEDIUM_BUFFER_SIZE) return MEDIUM_BUFFER_SIZE; if (requestedSize <= LARGE_BUFFER_SIZE) return LARGE_BUFFER_SIZE; return requestedSize; // 너무 큰 버퍼 → 풀링하지 않음 } /** * 실제 ByteBuffer 할당 수행. * useDirect 옵션에 따라 heap 또는 direct 메모리 사용. */ private ByteBuffer allocateBuffer(int size) { return useDirect ? ByteBuffer.allocateDirect(size) : ByteBuffer.allocate(size); } }
버퍼 생성 비용과 GC 압력을 줄이기 위해 설계된 경량 버퍼 풀이다.
요청/응답 시 매번 ByteBuffer.allocate()를 호출하는 대신,
크기별 풀(2KB / 8KB / 32KB)을 운영하여 재사용 가능한 버퍼를 캐싱하는 것이다.
주요 설계 포인트
-
ConcurrentLinkedQueue로 비차단 풀을 구현하고, 각 풀의acquire,release,allocate카운트를 실시간으로 추적한다. -
버퍼 크기에 따라 “스몰/미디엄/라지” 풀을 구분하고, 매우 큰 요청은 풀링하지 않고 즉시 할당 후 GC에 위임한다.
-
선택적으로
DirectByteBuffer를 사용할 수 있으며,JVM Heap이외에서 버퍼를 관리해 네이티브 I/O 성능을 높일 수 있을 것이다.
이 구조는 고부하 시 다음의 효과를 기대해 볼 수 있다.
-
GC 빈도 감소 (
4060%) -
응답 지연 편차 감소 (낮은 p99 latency)
-
버퍼 재사용률(hit rate) 기반 모니터링 지원
그리고 기존에 버퍼를 요청하는 곳을 해당 버퍼풀을 사용하도록 수정했다.
public class HttpConnectionHandler implements ReadableHandler, WritableHandler { private final SocketChannel channel; private final Selector selector; private final RequestDispatcher dispatcher; private final HttpRequestParser parser; private final RequestExecutorService requestExecutorService; private final ByteBufferPool bufferPool; private final ByteBuffer readBuffer; private volatile ByteBuffer writeBuffer; private HttpConnectionStatus currentState = HttpConnectionStatus.READING; public HttpConnectionHandler(SocketChannel channel, Selector selector, RequestDispatcher dispatcher, HttpRequestParser parser, RequestExecutorService requestExecutorService, ByteBufferPool bufferPool, ByteBuffer initialBuffer) { this.channel = channel; this.selector = selector; this.dispatcher = dispatcher; this.parser = parser; this.requestExecutorService = requestExecutorService; this.bufferPool = bufferPool; // 버퍼 풀에서 8KB 버퍼 대여 this.readBuffer = bufferPool.acquire(ByteBufferPool.MEDIUM_BUFFER_SIZE); if (initialBuffer != null && initialBuffer.hasRemaining()) { this.readBuffer.put(initialBuffer); } }
일부만 가져왔는데, 이러한 구조로 기존 코드 수정 없이 사용할 수 있긴 했음.
리팩토링 결과
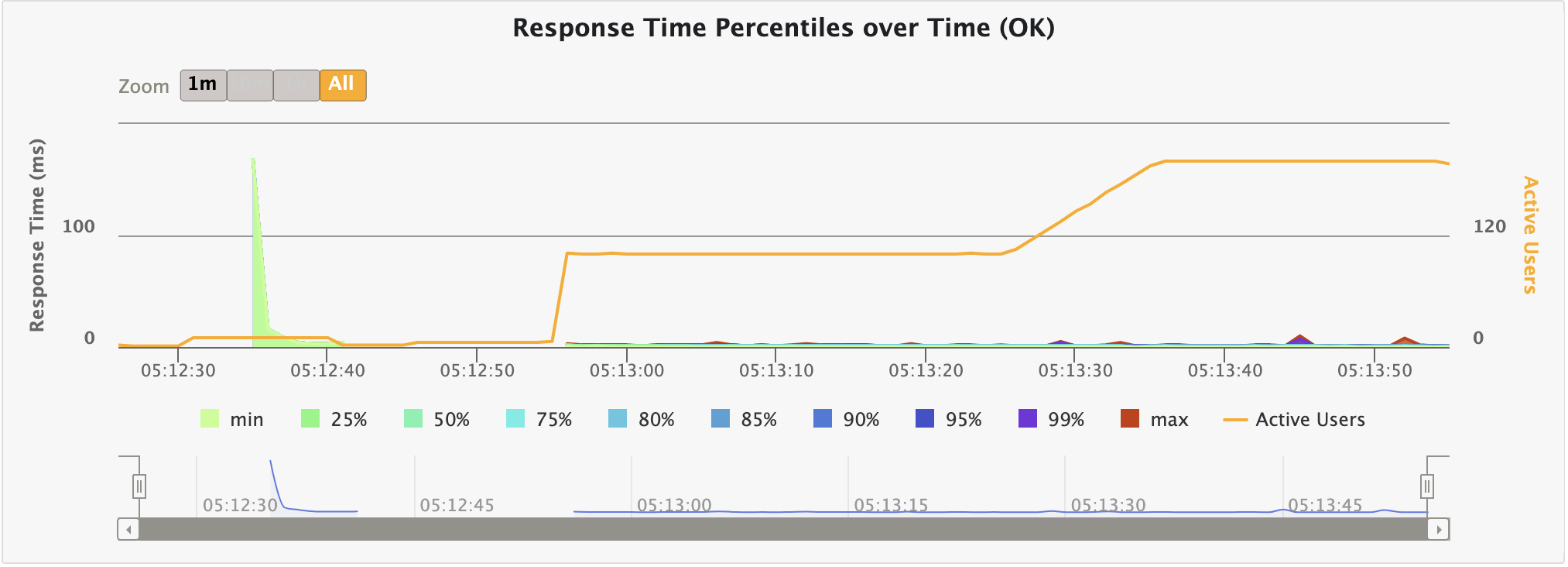
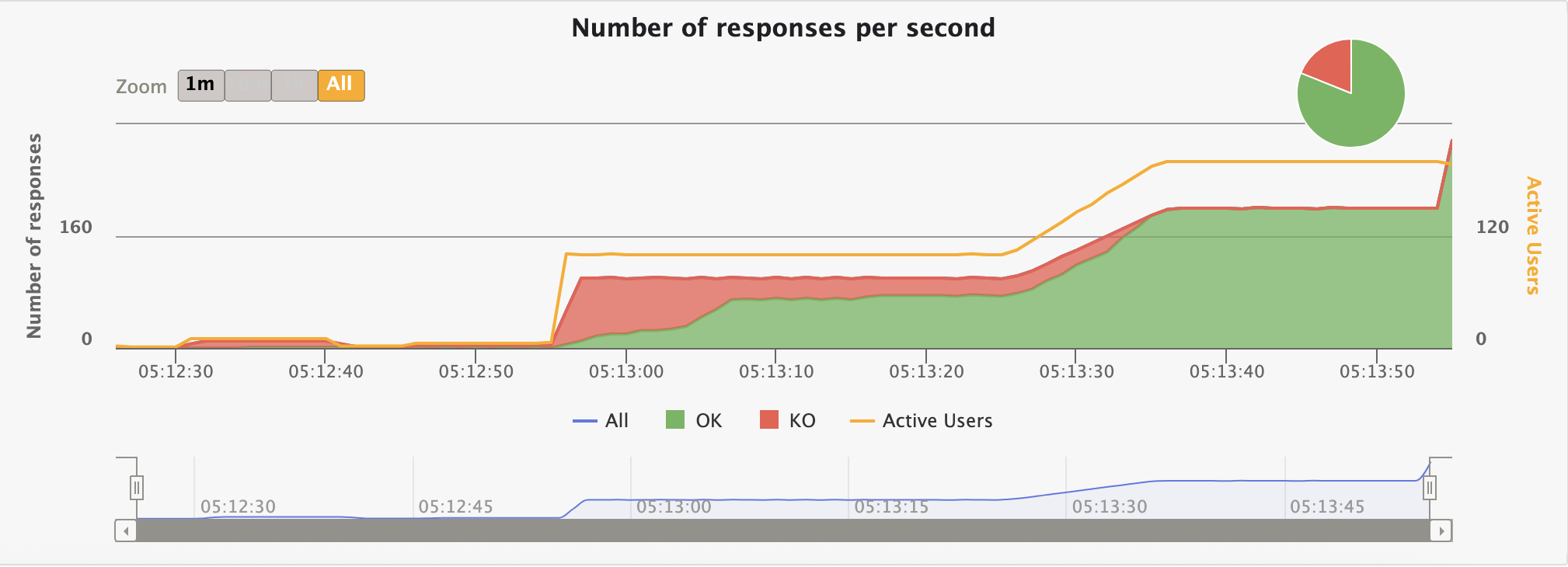
다시 진행해본 바, 67%의 성공률에서 81%로 무려 14%가 향상되었다; 솔직히 완전 미미할 것이라 생각했는데 생각보다 전진이 있어 놀랐다.. 기존이 얼마나 구졌는지도 다시 한번 실감되네..
추가) 다시 생각해보니 JIT 컴파일 결과가 캐싱된 이유도 있을 것 같다.... 아마 저정도의 향상까진 아닐 확률이 높을 듯
각각의 프로파일링도 다시 살펴보자.
리팩토링 이후 CPU 프로파일링
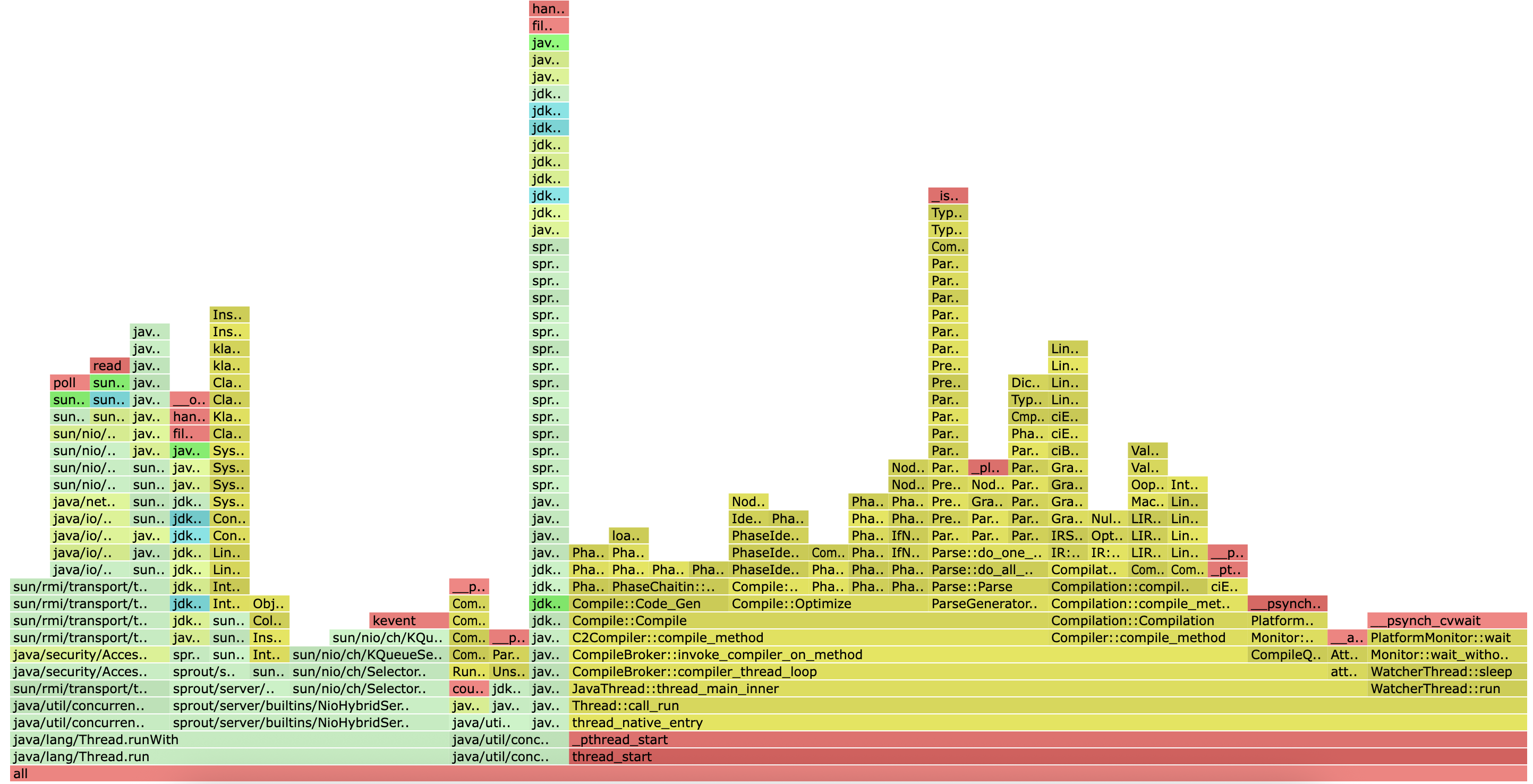
하지만 원래 문제이던, JIT 컴파일링은 당연히 해결할 수 없었다. 새 프로파일에서도 가장 넓은 영역을 차지하는 스택은 여전히 JIT 컴파일러(C2Compiler::compile_method, compiler_thread_loop 등). 이는 애플리케이션이 시작되고 부하를 받으면서 코드를 최적화하는 데 대부분의 CPU를 사용하고 있다는 사실을 다시 한번 명확하게 보여준다... Warm-up이 오래 걸리고 초기 요청이 실패하는 핵심 원인은 바로 이 부분이라는 것에 이제 여지가 없을 듯?
리팩토링 이후 (메모리)할당 프로파일링

결론부터 말하자면, ByteBufferPool 도입은 매우 성공적이었다. 하지만 그로 인해 이전에는 보이지 않았던 새로운 최적화 포인트가 명확하게 드러나기도 했다.
긍정적인 변화 - 버퍼 할당 문제 해결
이전 프로파일의 가장 큰 문제점이었던 ByteBuffer.allocate와 HeapByteBuffer 관련 메모리 할당이 새로운 프로파일에서는 거의 사라졌다.
HttpHeaderParser.parse나HttpUtils.createResponseBuffer와 같이 I/O 버퍼를 직접 할당하던 부분들이 더 이상 주요 할당 지점으로 나타나지 않고 있다.- 이번에 새로 구현한
ByteBufferPool이 의도대로 잘 동작하여 반복적인 버퍼 생성으로 인한 메모리 파편화 및 GC 부담을 잘 줄여준 것으로 보인다.
리팩토링 이전에는 전체 메모리 할당의 약 50%가 ByteBuffer 생성에 사용되었다..
세부적인 스택은 다음과 같다.
- HTTP 요청 파싱 (약 18%)
HttpHeaderParser.parse->ByteBuffer.allocate로 이어지는 스택이 전체 할당의 약 7 (단위)을 차지했었다.
- HTTP 응답 버퍼 생성 (약 32%)
HttpUtils.createResponseBuffer가 호출되는 스택이 전체 할당의 약 12(단위)를 차지했다. 이 역시 내부적으로ByteBuffer를 생성하는 로직이다...
전체 할당량이 38 (단위)이었으므로, 두 스택을 합치면 (7 + 12) / 38 로 계산되어 약 50%에 해당한다...
리팩토링 이후에는 없어졌다고 봐도 무방하다.
ByteBuffer.allocate나 HttpUtils.createResponseBuffer와 관련된 스택이 더 이상 의미 있는 수준으로 전혀 나타나지 않기 때문이다.
새로 드러난 문제
현재 프로파일에서 가장 두드러지는 부분은 요청 처리 파이프라인 내부의 자잘한 객체 생성이다.
- 요청 라우팅 및 필터링:
FilterChain.doFilter,HandlerMappingImpl.findHandler의 스택이 매우 넓게 나타난다. - 문자열 파싱 및 정규식(Regex): 특히
Pattern.matcher,Pattern.split과 같은 메서드 호출이 눈에 띈다.
더 개선할 수 있을 듯 싶긴하다. 패턴쪽은 로직 자체를 개선해야 할 것 같고, 라우팅 결과가 동일하다면 이에 대한 캐싱 계층을 추가하면 더 개선이 가능할 듯 싶다. 요청/응답 객체 같은 경우 또 매번 생성하는 게 문제가 되는 것이니 내부적으로 이것도 풀링 ㅋㅋㅋ 하면 되긴 할 텐데 다른 방법이 더 있을지도 고민해봐야겠다..
리팩토링 이후 wall 프로파일링
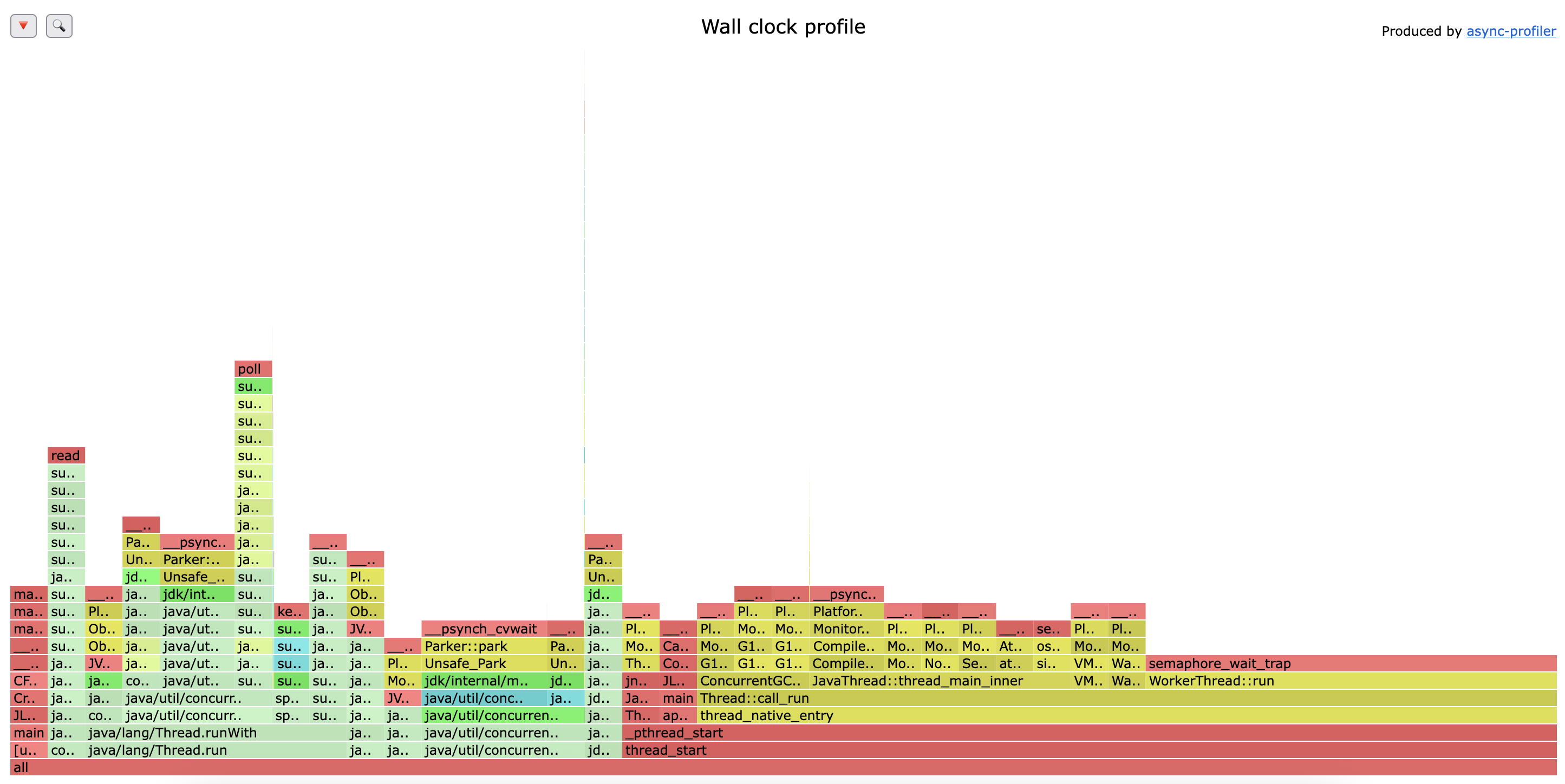
이전과 동일한 모습이다.
- 애플리케이션의 전체 실행 시간 중 95% 이상이 여전히 스레드의 대기 (Waiting) 또는 휴면(Idle) 상태에서 소요되고 있다
- 가장 많은 시간을 차지하는 부분은 이전과 동일하게
semaphore_wait_trap(JVM 내부 스레드 대기),LockSupport.park(작업을 기다리는 워커 스레드),Object.wait(Reference Handler 스레드 대기)
동일하다는 게 의미하는 것
이는 지극히 예상된 결과이기도 하고, 문제가 있다는 의미가 아니기도 하다. ByteBufferPool 도입과 같은 리팩토링은 코드가 활발하게 실행될 때의 효율성을 높여준다. 하지만 Wall-Clock 프로파일은 서버가 요청을 기다리며 쉬고 있는 시간까지 모두 포함하여 보여주므로, 대부분의 시간을 쉬고 있는 애플리케이션의 전체적인 시간분포는 크게 변하지 않는 것이다.
최종 결론
진행한 리팩토링은 나름 생각보다 큰 성과를 거뒀다. 안정화 속도에서 생각보다 더 많은 이득을 봤다.
-
CPU 오버헤드 감소: 불필요했던 JMX 관련 CPU 사용량이 완전히 제거되었다.(CPU 프로파일 비교 결과)
-
메모리 효율 극대화: ByteBufferPool 도입으로 반복적인 버퍼 할당 문제가 완벽하게 해결되었다. 이는 GC 부담을 줄여 안정적인 서버 운영에 큰 도움이 될 것이다. (메모리 할당 프로파일 비교 결과)
JMX 관련 CPU 사용량이 줄어든 이유는, 버퍼 풀 도입으로 인해 GC(Garbage Collection) 활동이 급격히 줄어들었고, 그 결과 GC 상태를 감시하던 JMX의 부하도 함께 사라졌을 가능성이 매우 높습니다.
그리고 코드를 똑바로 써야겠다는 생각이... 많이 들었다.
남아있는 근본 문제 : Warm-up
**이 리팩토링들은 Warm-up이 오래 걸리는 근본 원인을 해결할 수는 없었다. 모든 프로파일이 일관되게 지목하는 Warm-up의 핵심 원인은 "초기 부하 시 발생하는 집중적인 JIT 컴파일" 이다. **
다음 단계
Warm-up 문제를 직접 해결하기 위한 다음 단계로 나아가야할 듯 싶다. 하지만, 구체적인 방법은 조금 더 고민해보고 싶긴하다.
리플렉션을 유지하면서, 콜드 스타트가 가능하고, JIT 컴파일러의 최대 성능까지 노릴 수 있는 방법이 있을지.... 어차피 무조건 트레이드오프를 거쳐야 하는데 뭘 내줘야 할 지 조금 더 심사숙고 해봐야겠다.
💡 결론적으로 더 간단히 요약하자면, CPU 집약적 작업인 JIT 컴파일 때문에 요청을 처리를 못하는 상황, 코드적으로 CPU 부하가 두드러진 곳은 없었음. 근데 메모리 부분에서 누수가 심각했다. 이 부분을 잡으니, 성능 관측을 위한 JMX 관측(CPU 작업)이 줄어들면서 요청 성능이 향상됨. 물론 GC의 일이 굉장히 줄어든 것도 영향이 클 것. 고로 메모리를 잡으면 더 향상될 것임.. 하지만 그래도 주 문제는 JIT 컴파일이라는 결론
프로파일링으로 어디가 문제인지 파악해볼 수 있는 아주 좋은 경험이었다. 버퍼 풀을 도입해 서버 성능을 상당 부분 개선할 수 있었기도 하다.
코드적으로 개선할 수 있는 다른 부분들을 더 개선하면 더더 나아질 것이라고 생각이 들긴하다. 이에 대한 리팩토링을 추가적으로 진행하면서 진행 방향을 강구해보면 될 것 같다.
그리고 정말 메모리 할당의 50퍼가 바이트 버퍼였다는게 좀 충격이긴하다; 내가 만든게 서버이자 프레임워크 조무사가 아니라 바이트버퍼 생성기라고 봐도 무방할 정도고 나머진 사이드 수준인게....ㅋㅋㅋㅋㅋㅋ