JMC + JITWatch로 본 JIT 컴파일의 세계
내가 만든 HTTP 서버가 JVM에서 어떻게 최적화되는가
실험 요약
- 주요 병목: HttpUtils.readRawRequest, ClassLoader, ObjectOutputStream
- 인라이닝 실패 이유: 메서드 크기 초과, 스택 초과, 예측 불가능한 분기
- GC 영향: 전체 실행 시간 대비 0.03%
- 개선 포인트: 메서드 분리, 조기 리턴 구조, 객체 풀링
전제 지식
이전 실험↗에서 왜 "JIT 컴파일"이 문제가 되는지 async-profiler 실험에서 이미 설명한 바가 있기때문에 해당 사실에 대해서는 이미 알고 있다고 전제하겠습니다.
일단 전편에 이어 이번엔 정확히 어디에서 JIT 컴파일이 이루어지는지 찾아야 한다. JIT 컴파일은 내부적으로 메서드 인라이닝, 스칼라 치환, 탈출 분석, 잠금 제거 및 병합 등을 수행하면서 네이티브 코드의 성능을 향상시키는데에 목적이 있다. 이러한 JIT 컴파일이 유리하게 애초에 코드를 작성하는 게 성능향상에 도움이 됨.
다만, 어디에서 주로 JIT 컴파일이 이루어지는 지 정확히 파악하고 해당 부분에 개선을 해야하기 때문에, 이를 파악하기 위해 JMC(JDK Mission Control), JIT Watch를 사용해봤다.
고로 이번 포스팅에선 원인을 분석(어디에서 JIT 컴파일이 수행되는지 찾기)하는데에 집중해보고자 한다. 바로 후속편으로 이에 대한 조치를 취하고 얼만큼의 성능향상을 이룩했는지 작성할 예정이다.
JMC, JIT Watch 등 사용에 미숙한 면이 많습니다. 만약 잘못 파악하고 있다면 첨언 부탁드려요 🙇♀️
JMC란?
Java Mission Control (JMC)은 Java 애플리케이션의 성능 모니터링 및 진단을 위한 도구입니다. Oracle JDK에 포함되어 있으며, JVM의 런타임 동작을 분석하고 최적화하는 데 사용됩니다.
주요 기능
- Flight Recorder (JFR): 애플리케이션의 상세한 런타임 데이터를 수집하여 성능 병목 현상, 메모리 누수, 스레드 문제 등을 분석.
- 실시간 모니터링: CPU 사용량, 메모리 할당, 가비지 컬렉션 등의 실시간 정보 제공.
- 프로파일링: 메서드 호출, 스레드 상태, 힙 사용량 등을 시각화하여 성능 최적화에 도움.
- 사용자 친화적 인터페이스: 그래프, 차트, 테이블로 데이터를 직관적으로 표시.
JIT Watch란?
JITWatch는 Java HotSpot JVM의 Just-In-Time (JIT) 컴파일러 동작을 분석하고 시각화하는 오픈소스 도구입니다. AdoptOpenJDK에서 개발되었으며, JVM의 컴파일 로그(hotspot.log)를 처리하여 개발자들이 JIT 최적화 과정을 이해하고 성능을 개선할 수 있도록 돕습니다.
주요 기능
- 인라인 결정 분석: 메서드 인라이닝 여부와 이유를 검사.
- 핫 메서드 및 컴파일 순서 추적: 자주 호출되는 메서드의 컴파일 순서와 최적화 수준 표시.
- 바이트코드 및 어셈블리 뷰: 소스 코드, 바이트코드, 어셈블리 코드를 동시에 비교하여 시각화.
- JavaFX 기반 UI: 그래프와 테이블로 로그 데이터를 직관적으로 탐색.
Gatling이란?
Gatling은 오픈소스 부하 테스트 도구로, 주로 웹 애플리케이션의 성능 및 부하 테스트를 위해 사용됩니다. Scala로 작성되었으며, Akka와 Netty를 기반으로 비동기 방식으로 높은 성능을 제공합니다.
- 시나리오 기반 테스트: 사용자가 실제 사용자 행동을 시뮬레이션하는 테스트 시나리오를 Scala DSL로 작성.
- 높은 성능: 비동기 I/O를 활용해 적은 리소스로 수십만 사용자 트래픽 시뮬레이션 가능.
- 상세 리포팅: HTML 형식의 직관적인 보고서로 응답 시간, 처리량, 에러율 등을 시각화.
- 확장성: HTTP, WebSocket, JMS 등 다양한 프로토콜 지원.
- 오픈소스 및 엔터프라이즈 버전: 무료 오픈소스 버전과 클라우드 기반의 Gatling Enterprise 제공.
지난번처럼 부하 테스트 자체는 Gatling을 사용했습니다.
우선, hotspot.log와 jfr을 수집해야하기 때문에 인텔리제이에 다음과 같은 vm 옵션을 추가해야합니다.
사용한 JVM 옵션
-XX:StartFlightRecording=filename=jit-profile/recording.jfr,duration=300s,settings=profile -XX:+UnlockDiagnosticVMOptions -XX:+LogCompilation -XX:LogFile=jit-profile/hotspot_%p.log -XX:+PrintInlining -XX:+PrintCompilation -XX:+PrintCodeCache -XX:+PrintAssembly -XX:PrintAssemblyOptions=intel -XX:CompileCommand=print,*benchmark* -XX:+DebugNonSafepoints
상세설명
-
-XX:StartFlightRecording=filename=jit-profile/recording.jfr,duration=300s,settings=profile
- 설명: Java Flight Recorder(JFR)를 시작하여 JVM의 런타임 데이터를 기록
- 세부사항
filename=jit-profile/recording.jfr: 기록된 데이터를jit-profile/recording.jfr파일에 저장duration=300s: 기록을 300초 동안 진행settings=profile: JFR의 'profile' 설정 템플릿을 사용해 상세한 성능 데이터를 수집(CPU, 메모리, 스레드 등).
- 용도: 성능 병목 지점 분석 및 최적화에 사용
-
-XX:+UnlockDiagnosticVMOptions
- 설명: JVM의 진단용 옵션들을 활성화
- 세부사항: 기본적으로 비활성화된 고급 디버깅 및 진단 옵션(예:
LogCompilation,PrintInlining)을 사용 가능하게 함 - 용도: 실험적 또는 디버깅 옵션을 사용할 때 필수
-
-XX:+LogCompilation
- 설명: JIT 컴파일러의 컴파일 활동을 로그로 기록
- 세부사항: 컴파일된 메서드, 최적화 결정 등을 로그 파일에 기록, 출력은
-XX:LogFile로 지정한 파일로 저장됨 - 용도: JIT 컴파일 동작 분석, 예를 들어 JITWatch와 함께 사용.
-
-XX:LogFile=jit-profile/hotspot_%p.log
- 설명: JVM 로그(예:
LogCompilation출력)의 저장 경로를 지정 - 세부사항:
%p는 프로세스 ID를 나타내며, 로그 파일은jit-profile/hotspot_<PID>.log로 생성 - 용도: 로그 파일을 특정 경로에 저장하여 분석
- 설명: JVM 로그(예:
-
-XX:+PrintInlining
- 설명: JIT 컴파일러의 인라이닝 결정을 출력
- 세부사항: 메서드 인라이닝 성공/실패 여부와 이유를 로그에 기록
- 용도: 인라이닝 최적화 분석으로 성능 병목 지점 파악
-
-XX:+PrintCompilation
- 설명: JIT 컴파일러가 메서드를 컴파일할 때마다 해당 정보를 출력
- 세부사항: 컴파일된 메서드 이름, 크기, 컴파일 레벨(C1/C2) 등을 콘솔 또는 로그에 기록
- 용도: JIT 컴파일 프로세스 모니터링
-
-XX:+PrintCodeCache
- 설명: JIT 컴파일된 코드가 저장되는 코드 캐시의 상태를 출력
- 세부사항: 코드 캐시 사용량, 크기, 청소 여부 등을 로그에 기록
- 용도: 코드 캐시 메모리 관리 문제 진단
-
-XX:+PrintAssembly
- 설명: JIT 컴파일러가 생성한 네이티브 어셈블리 코드를 출력
- 세부사항: 컴파일된 메서드의 기계어 코드를 표시. 외부 디스어셈블러(hsdis 라이브러리) 필요
- 용도: 저수준 최적화 분석
-
-XX:PrintAssemblyOptions=intel
- 설명: 어셈블리 코드 출력 형식을 Intel 스타일 구문으로 지정
- 세부사항: 기본적으로 AT&T 구문이 사용되지만,
intel설정으로 더 읽기 쉬운 Intel 구문 사용 - 용도: 어셈블리 코드 가독성 개선
-
-XX:CompileCommand=print,benchmark
- 설명: 특정 메서드(여기서는
*benchmark*패턴에 매칭되는 메서드)에 대해 컴파일 정보를 출력하도록 지정 - 세부사항:
print는 해당 메서드의 컴파일 과정을 상세히 로그로 기록 - 용도: 특정 메서드의 JIT 컴파일 동작 분석
- 설명: 특정 메서드(여기서는
-
-XX:+DebugNonSafepoints
- 설명: JVM의 비-세이프포인트(safepoint) 위치에서도 디버깅 정보를 생성하도록 설정
- 세부사항: JFR이나 기타 디버깅 도구에서 더 상세한 스택 추적 및 런타임 정보 수집 가능
- 용도: 세밀한 성능 분석 및 디버깅
어셈블리 수준의 최적화를 진행할 것이 아니라면 당연히 해당 옵션은 필요없습니다.. 저는 그냥 궁금해서 열어봤어요.
사용한 벤치마킹 시나리오
기존의 아주 간단한 Hello 시나리오는 모자랄 것 같아, 더 큰 부하를 가하는 시나리오를 새로 작성했습니다. 우선은 warm-up에 대한 문제를 해결하기 위함이고, 초반에 JIT 컴파일이 어디서 나타나는지 찾기 위함이니 요청 수를 높게 설정했습니다.
package benchmark; import io.gatling.javaapi.core.*; import io.gatling.javaapi.http.*; import static io.gatling.javaapi.core.CoreDsl.*; import static io.gatling.javaapi.http.HttpDsl.*; import java.time.Duration; /** * Heavy Load Simulation for JIT Profiling * - Warm-up: ~20,000 requests * - Load test: ~80,000 requests * - Total: ~100,000 requests */ public class HeavyLoadSimulation extends Simulation { HttpProtocolBuilder httpProtocol = http .baseUrl("http://localhost:8080") .acceptHeader("text/plain,application/json") .userAgentHeader("Gatling Heavy Load Test") .shareConnections() // 커넥션 재사용 .disableFollowRedirect() .disableWarmUp() // Gatling 기본 warm-up 비활성화 .maxConnectionsPerHost(500) .connectionHeader("keep-alive") .header("Keep-Alive", "timeout=5, max=1000"); // Warm-up 시나리오: 약 20,000 요청 // 목적: 서버 JVM JIT 컴파일, 스레드풀, 커넥션 풀 예열 ScenarioBuilder warmUp = scenario("Warm-up Phase") .exec( http("Warm-up request") .get("/benchmark/hello") .check(status().is(200)) ); // Heavy Load 시나리오: 약 80,000 요청 // 목적: JIT 컴파일 완료 후 steady-state 성능 측정 ScenarioBuilder heavyLoad = scenario("Heavy Load Test") .exec( http("GET /benchmark/hello") .get("/benchmark/hello") .check(status().is(200)) ); { setUp( // ======================================== // Phase 1: Warm-up (~20,000 requests) // ======================================== warmUp.injectOpen( // 점진적 증가: 0 -> 100 RPS (5초) rampUsersPerSec(0).to(100).during(Duration.ofSeconds(5)), // 안정적 부하: 100 RPS (10초) = 1,000 requests constantUsersPerSec(100).during(Duration.ofSeconds(10)), // 중간 부하: 300 RPS (20초) = 6,000 requests constantUsersPerSec(300).during(Duration.ofSeconds(20)), // 고부하: 500 RPS (25초) = 12,500 requests constantUsersPerSec(500).during(Duration.ofSeconds(25)) // Total: ~19,500 requests ).protocols(httpProtocol), // ======================================== // Phase 2: Heavy Load (~80,000 requests) // ======================================== heavyLoad.injectOpen( // warm-up 완료 대기 nothingFor(Duration.ofSeconds(60)), // 점진적 램프업: 100 -> 1000 RPS (10초) rampUsersPerSec(100).to(1000).during(Duration.ofSeconds(10)), // 고부하 구간 1: 1000 RPS (30초) = 30,000 requests constantUsersPerSec(1000).during(Duration.ofSeconds(30)), // 최대 부하: 1000 -> 1500 RPS (10초) rampUsersPerSec(1000).to(1500).during(Duration.ofSeconds(10)), // 고부하 구간 2: 1500 RPS (30초) = 45,000 requests constantUsersPerSec(1500).during(Duration.ofSeconds(30)), // 점진적 감소: 1500 -> 500 RPS (10초) rampUsersPerSec(1500).to(500).during(Duration.ofSeconds(10)) // Total: ~80,000 requests ).protocols(httpProtocol) ) .assertions( // 최대 응답시간 1초 이하 global().responseTime().max().lt(1000), // 95 percentile 응답시간 500ms 이하 global().responseTime().percentile3().lt(500), // 성공률 99% 이상 global().successfulRequests().percent().gt(99.0), // 초당 요청 처리량 (throughput) 체크 global().requestsPerSec().gt(500.0) ); } }
시나리오 설명
HeavyLoadSimulation은 Gatling을 사용한 Java 애플리케이션 부하 테스트 시나리오로, JIT 컴파일 프로파일링을 위해 설계했습니다. 약 100,000개의 HTTP 요청을 생성하며, 두 단계로 구성됩니다.
-
Warm-up Phase (~20,000 요청)
- 목적: 서버 JVM의 JIT 컴파일, 스레드 풀, 커넥션 풀 예열
- 시나리오:
/benchmark/hello엔드포인트에 GET 요청 - 부하 패턴: 0→100 RPS(5초), 100 RPS(10초), 300 RPS(20초), 500 RPS(25초).
- 총 요청: 약 19,500
-
Heavy Load Phase (~80,000 요청)
- 목적: JIT 컴파일 완료 후 안정 상태(steady-state) 성능 측정
- 시나리오: 동일 엔드포인트(
/benchmark/hello)에 GET 요청 - 부하 패턴: 60초 대기 후, 100→1000 RPS(10초), 1000 RPS(30초), 1000→1500 RPS(10초), 1500 RPS(30초), 1500→500 RPS(10초)
- 총 요청: 약 80,000
HTTP 설정
- 기본 URL:
http://localhost:8080. - 커넥션 재사용, 최대 500개 커넥션, Keep-Alive 설정
- Warm-up 비활성화, 리다이렉트 비활성화
검증 조건
- 최대 응답 시간: 1초 미만
- 95% 응답 시간: 500ms 미만
- 성공률: 99% 이상
- 초당 요청: 500 이상
이 스크립트는 JVM의 JIT 최적화 동작을 분석하기 위해 초기 예열 후 고부하 테스트를 수행하며, 성능 지표를 엄격히 검증하고자 했습니다.
사용 서버 모델
지금까지 제가 직접 만들었던 프레임워크이자 서버가 모델입니다.
구조 설명 보러가기↗ 최초 성능 테스트 보러가기↗ async-profiler를 사용한 성능 개선기 보러가기↗
이번에 선정한 모델은 hybrid + VT 조합이고 가장 안정적일 것이라 기대되는 모델을 골랐습니다. 해당 조합에서도 JIT 컴파일 관련 문제는 동일하게 발생했습니다.
톰캣과 비슷한 구조로 동작하는 모델입니다.
지금까지의 성능 개선 내역
-
async-profiler를 사용하여 메모리 할당에 큰 문제가 있던 부분을 개선- 내부적으로
byteBuffer할당이 잦아 해당 부분에ByteBufferPool을 도입하여 GC 압박 감소 -> JMX 부하(CPU 작업, 메트릭 수집을 위한 작업입니다) 감소 -> 결론적으로 CPU에 비교적 여유가 발생하여 성능 향상
- 내부적으로
-
해당 성능 개선 이후,
controller를 찾는 부분에 있어Pattern매칭과 관련하여 메모리 할당이 잦아 해당 부분에 간단한 캐싱 계층 추가.- 해당 부분에 있어선 아주 간단한 조치여서 구체적인 성능 계측까진 진행하진 않았습니다.
// 기존에 사용하던 캐시 private final Map<PathPattern, Map<HttpMethod, RequestMappingInfo>> mappings = new ConcurrentHashMap<>(); // 개선을 위해 추가한 캐시 private final Map<String, PathPattern> pathPatterns = new ConcurrentHashMap<>();로직 초반에 다음과 같은 추가 리턴문을 두어 캐싱하도록 하였습니다.
if (pathPatterns.containsKey(path)) { return mappings.get(pathPatterns.get(path)).get(httpMethod); } // 생략 pathPatterns.put(path, matchingHandlers.getFirst().pattern());약간의 메모리 개선, 이로 인한 GC 압력이 어느정도 감소했을 것이라 추측됩니다.
Gatling 부하 테스트 + JIT 프로파일링 자동화 스크립트
#!/bin/bash OUTPUT_DIR="./jit-profile" PORT=8080 # ================================================ # 준비 # ================================================ mkdir -p "$OUTPUT_DIR" echo "════════════════════════════════════════════════════════════════" echo " 🌱 Sprout JIT Profiling with Gatling" echo "════════════════════════════════════════════════════════════════" echo "" # ================================================ # 서버 구동 확인 # ================================================ echo "[1/3] Checking if Sprout server is running..." if ! curl -s "http://localhost:$PORT/benchmark/hello" > /dev/null 2>&1; then echo "" echo "Server is NOT running on port $PORT" echo "" echo "Start the server from IntelliJ with these VM options:" echo "────────────────────────────────────────────────────────────────" cat << 'VMEOF' --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=java.base/java.lang.reflect=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/java.util=ALL-UNNAMED -XX:StartFlightRecording=filename=jit-profile/recording.jfr,duration=300s,settings=profile -XX:+UnlockDiagnosticVMOptions -XX:+LogCompilation -XX:LogFile=jit-profile/hotspot_%p.log -XX:+PrintInlining -XX:+PrintCompilation -XX:+PrintCodeCache -XX:+PrintAssembly -XX:PrintAssemblyOptions=intel -XX:CompileCommand=print,*benchmark* -XX:+DebugNonSafepoints VMEOF echo "────────────────────────────────────────────────────────────────" echo "" exit 1 fi echo "✓ Server is running on port $PORT" echo "" # ================================================ # Gatling 부하 테스트 # ================================================ echo "[2/3] Running Gatling Heavy Load test..." echo "────────────────────────────────────────────────────────────────" echo " Simulation: HeavyLoadSimulation" echo " Warm-up: ~20,000 requests" echo " Load test: ~80,000 requests" echo " Total: ~100,000 requests" echo "────────────────────────────────────────────────────────────────" echo "" # Gatling 실행 ./gradlew gatlingRun --simulation=benchmark.HeavyLoadSimulation GATLING_EXIT_CODE=$? if [ $GATLING_EXIT_CODE -ne 0 ]; then echo "" echo "Gatling test failed with exit code: $GATLING_EXIT_CODE" exit $GATLING_EXIT_CODE fi echo "" echo "✓ Gatling test completed" echo "" # ================================================ # 결과 정리 # ================================================ echo "[3/3] Collecting profiling results..." echo "" # Gatling 리포트 경로 찾기 LATEST_GATLING_REPORT=$(find build/reports/gatling -type d -name "*HeavyLoadSimulation*" 2>/dev/null | sort -r | head -n 1) echo "════════════════════════════════════════════════════════════════" echo " Profiling Complete!" echo "════════════════════════════════════════════════════════════════" echo "" echo "Profiling Data:" echo " • JIT Compilation Log: $OUTPUT_DIR/hotspot_*.log" echo " • JFR Recording: $OUTPUT_DIR/recording.jfr" echo " • Assembly Output: $OUTPUT_DIR/hotspot_*.log (if hsdis available)" echo "" echo "Gatling Report:" if [ -n "$LATEST_GATLING_REPORT" ]; then echo " • HTML Report: $LATEST_GATLING_REPORT/index.html" echo "" echo " Open report:" echo " open $LATEST_GATLING_REPORT/index.html" else echo " • Check: build/reports/gatling/" fi echo "" echo "Analysis Tools" echo " 1. JITWatch: Analyze hotspot_*.log for JIT compilation details" echo " 2. JDK Mission Control: Open recording.jfr for performance profiling" echo " 3. Gatling: View HTML report for load test metrics" echo "" echo "════════════════════════════════════════════════════════════════"
스크립트 요약
이 스크립트는 Gatling을 사용한 부하 테스트와 JVM의 JIT 프로파일링을 자동화하여 Java 애플리케이션의 성능을 분석하도록 작성한 스크립트입니다.
-
준비 단계
./jit-profile디렉토리를 생성하여 결과 파일을 저장- 서버가
localhost:8080에서 실행 중인지 확인 - 서버가 실행 중이 아니면, IntelliJ에서 실행해야 할 JVM 옵션(예: JFR, JIT 로그 활성화)을 출력하고 종료
-
Gatling 부하 테스트
HeavyLoadSimulation클래스를 실행하여 약 100,000개의 요청 생성- Warm-up(~20,000 요청)과 Heavy Load(~80,000 요청)로 나뉘어 부하 테스트 수행
- 테스트 실패 시 종료 코드를 반환하며 종료
-
결과 정리
- JFR 파일(
recording.jfr), JIT 컴파일 로그(hotspot_*.log), Gatling HTML 리포트를 수집
- JFR 파일(
주요 출력
- JIT 로그:
jit-profile/hotspot_*.log(JITWatch로 분석) - JFR 파일:
jit-profile/recording.jfr(JMC로 분석) - Gatling 리포트:
build/reports/gatling/*/index.html(성능 메트릭 확인)
그냥 서버 실행하고 해당 스크립트 실행하면 됩니다. 위에서 설명했던 Gatling 시나리오 실행하고 리포트 위치를 알려줍니다.
Gatling 결과
솔직히 십만요청..? 걍 서버 뻗을까봐 굉장히 쫄렸음..
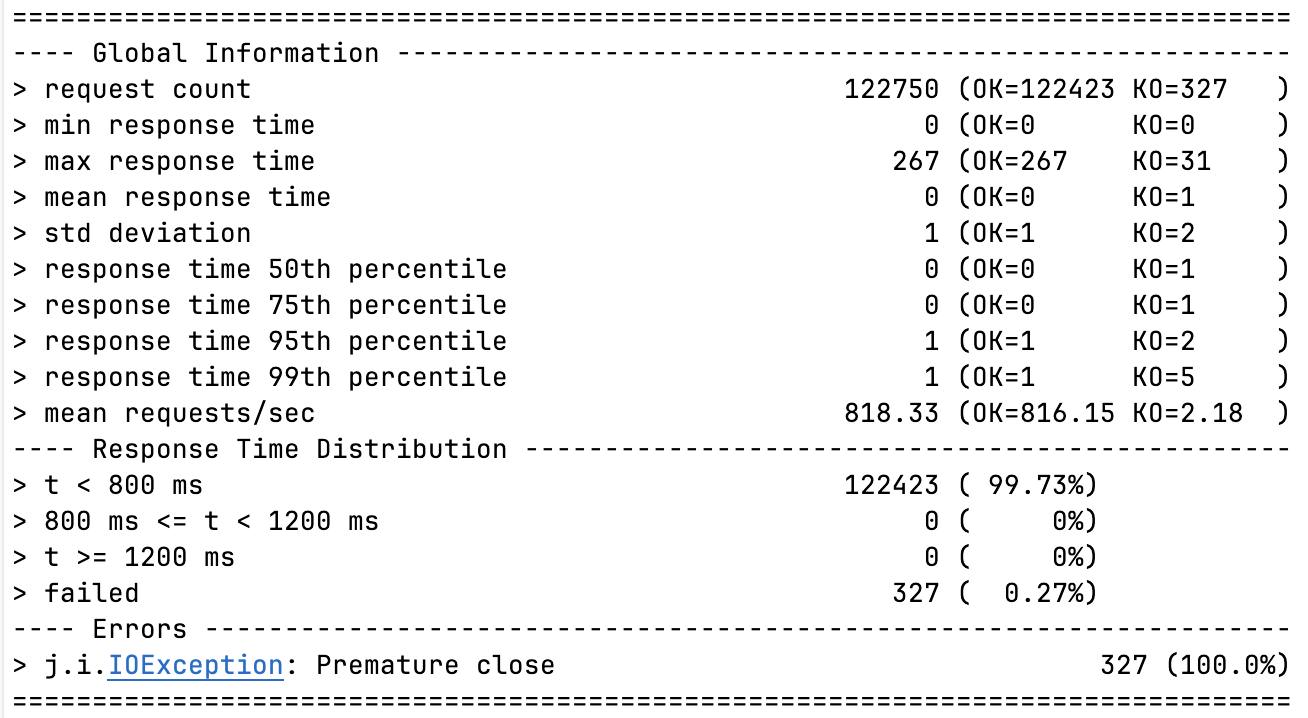
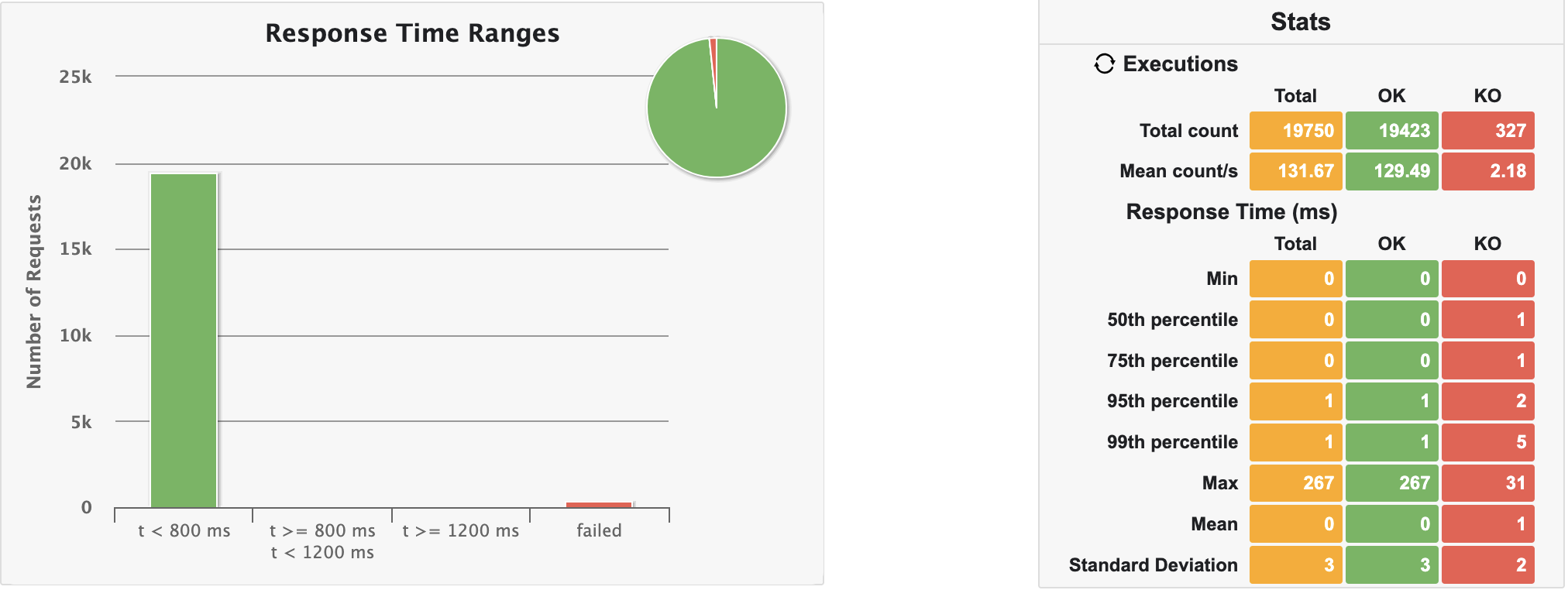
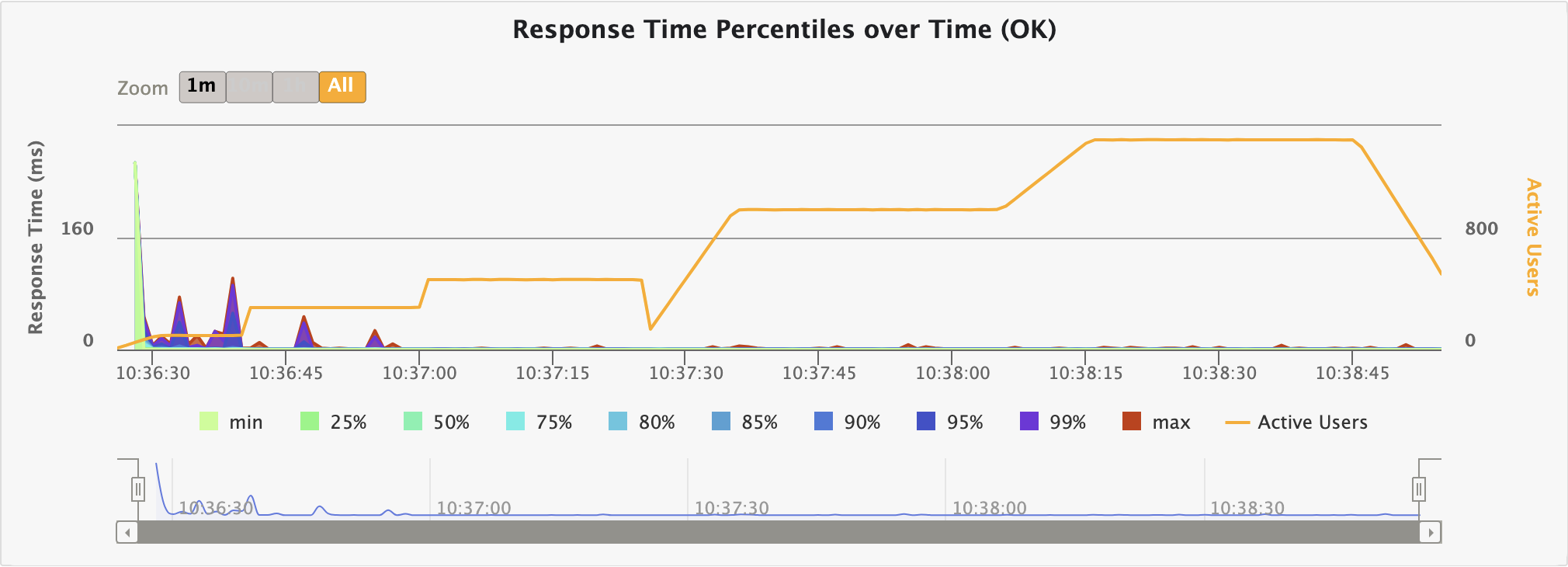
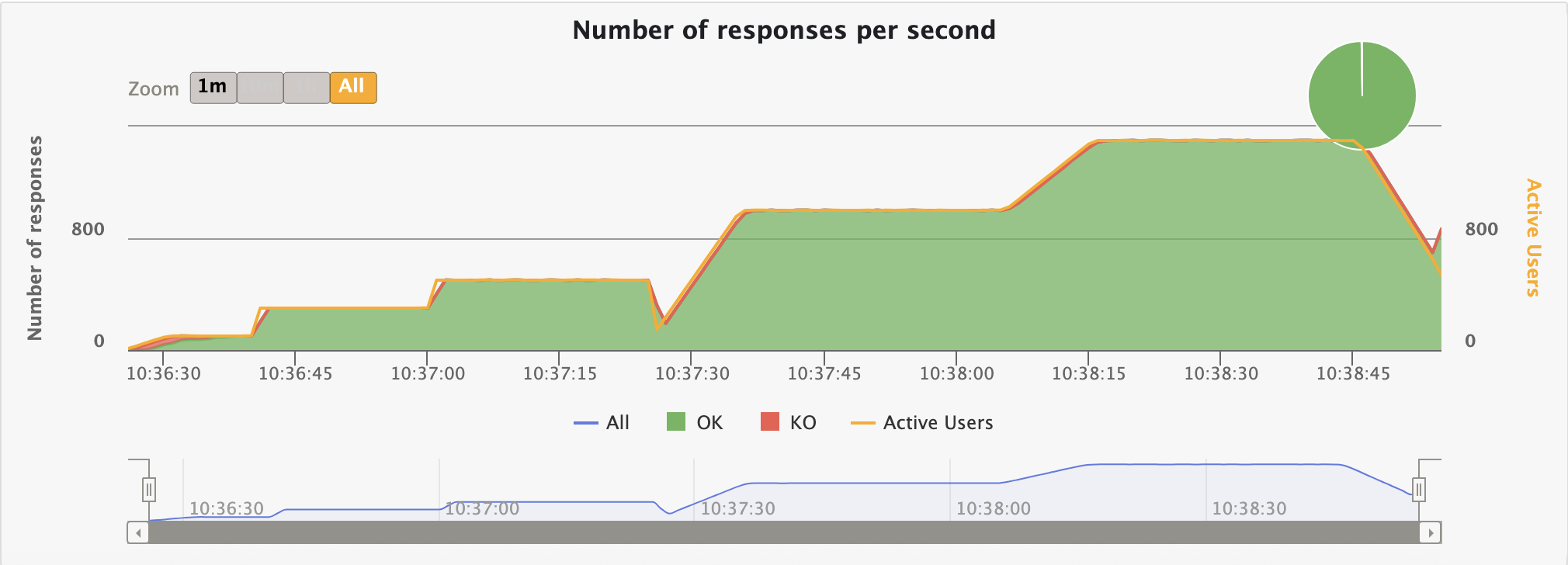
테스트 자체는 2분 29초 정도 소요되었구요, 요청을 생각보단 그래도 잘 처리하긴 하네요...?(99.73%) 역시 마찬가지로 초기 warm-up이 문제이고, JIT 컴파일이 잘 이루어진 경우엔 KO가 발생하지 않습니다.
KO 없이 요청이 잘 이루어지는 시간 분기점은 서버 실행 후 약 1분 뒤임을 그래프에서 확인할 수 있었습니다.
이제 정확히 어디서 컴파일이 발생하는지 찾아보면 됩니다.
JMC 분석
 JDK Mission Control을 열고
JDK Mission Control을 열고 .jfr 파일을 Import 해줍니다.
JIT 컴파일링 정보
JMC에서 JIT 컴파일에 대한 정보는 왼쪽 Compliations 탭에 위치합니다.
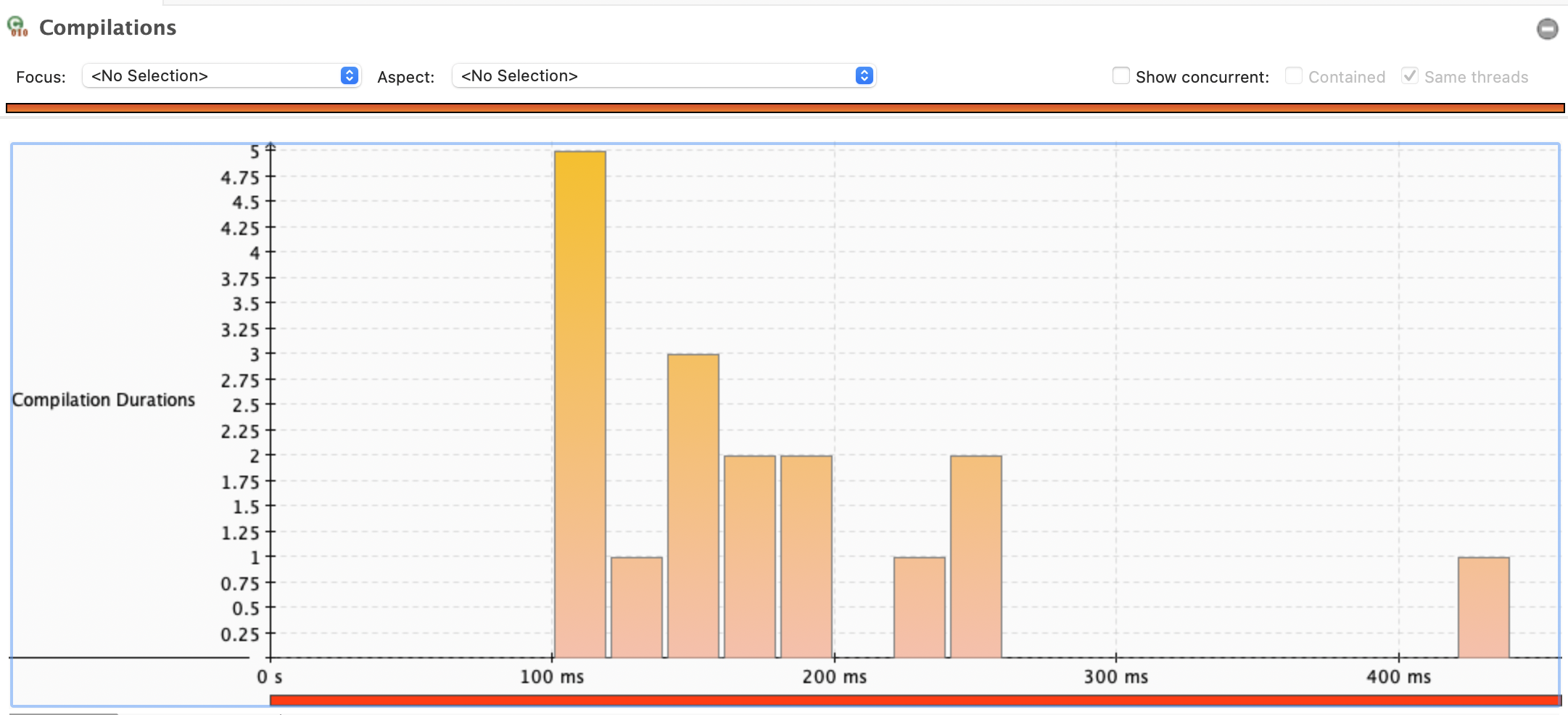 해당 그래프는 JVM의 JIT 컴파일러가 메서드를 컴파일하는 데 걸리는 시간(Compilation Duration)을 시각적으로 보여주고 있다.
해당 그래프는 JVM의 JIT 컴파일러가 메서드를 컴파일하는 데 걸리는 시간(Compilation Duration)을 시각적으로 보여주고 있다.
그래프 개요
- 제목: "Compilations" (컴파일 작업).
- Y축: 컴파일 지속 시간(Compilation Duration), 단위는 초(s).
- X축: 시간 경과, 단위는 밀리초(ms)로 표시(0ms, 100ms, 200ms, 300ms, 400ms)
- 데이터: 컴파일 작업의 빈도와 지속 시간을 바 형태로 나타냄
- 설정: "Same threads" 옵션이 선택되어 동일 스레드에서의 컴파일만 표시됨
주요 관찰
-
컴파일 시간 분포
- 대부분의 컴파일 작업은 0.75초에서 1.25초 사이에서 집중적으로 발생했음
- 특정 시점(약 100ms 부근)에서 컴파일 시간이 4.75초에 달하는 피크가 있음. 이는 JIT 컴파일러가 복잡하거나 크기가 큰 메서드를 처리했음을 나타낸다
- 200ms, 300ms, 400ms 부근에서는 컴파일 시간이 1.5초에서 2.75초 사이로 분포
-
피크 분석
- 100ms 지점의 높은 바(4.75초)는 초기 JIT 컴파일(예: Warm-up 단계)이나 주요 메서드의 최적화가 이루어진 시점을 반영할 수 있음
- 이후 시간이 지남에 따라 컴파일 시간이 감소하거나 안정화되는 경향이 보인다. 이는 Gatling의 해석과도 맞물림
해석
- 성능 영향: 4.75초에 달하는 피크는 애플리케이션 초기 부하(예: Gatling Warm-up 단계)에서 JIT 컴파일러가 많은 리소스를 소모했음을 시사. 이는 정상적인 초기 최적화 과정일 수 있으나, 지나치게 길면 성능 병목 가능성이 있음.
- 안정화: 200ms 이후 컴파일 시간이 1.5~2.75초로 줄어드는 것은 JIT 컴파일러가 안정적인 상태에 도달했음을 보여줌
이제 해당하는 작업이 뭔지 보면 된다. 가장 피크인 부분부터 보자.

이게 가장 긴(4.75s)에 달하던 로직들이다. JIT는 해당 부분이 코드적으로 빨라져야 한다고 생각했던 것임..
-
aseLocale sun.util.locale.BaseLocale.getInstance(String, String, String, String): Java의 로케일(Locale) 정보를 생성하는 메서드인데, 내가 작성한 애플리케이션에는 로케일 관련 작업은 따로 없음. 인스턴스 생성 자체에 필요한 로직 -
Resource jdk.internal.loader.URLClassPath$JarLoader.getResource(String, boolean): 이 메서드는 클래스 로더가 동적으로 리소스(설정 파일, 라이브러리 등)를 로드할 때 호출된다. 성능 피크는 클래스 로드 빈도가 높다는 것을 의미함. -
String sprout.server.HttpUtils.readRawRequest(ByteBuffer, InputStream): 제가 작성한 HttpUtils 클래스 내 readRawRequest 메서드. ByteBuffer와 InputStream을 사용해 HTTP 요청 데이터를 읽는 역할을 함. 실행 시간이 길다면 I/O 처리나 데이터 변환에서 병목이 있을 것이다.. -
boolean jdk.internal.org.objectweb.asm.Frame.merge(SymbolTable, Frame, int): 이는 동적 바이트코드 생성이나 변환(예: JIT 컴파일, 프록시 생성 등)이 발생할 때 호출된다. -
void java.io.ObjectOutputStream.writeOrdinaryObject(Object, ObjectStreamClass, boolean): 객체를 직렬화하여 네트워크나 파일로 전송할 때 호출, 근데 당연히 십만번 호출하면.. 컴파일 하고 싶을듯?
또 다른 병목 지점들을 살펴보자. JIT 컴파일의 이유에 대해서 정확히 유추할 필요는 없다. 조금이따 JIT Watch로 확인할 수 있음.
 이 부분은 약
이 부분은 약 3ms정도 소요됨.
 이 스레드에서는 약
이 스레드에서는 약 2ms 정도 소모,
 디스패처에 요청 할당시키는 부분에서도 컴파일에
디스패처에 요청 할당시키는 부분에서도 컴파일에 2ms정도 소모됨.
내가 작성한 로직에 대해서는 이정도 였고 나머진 또 바이트코드 조작 부분이 대부분이었음. java assist 같은..ㅇㅇ
사실 전편의 async-profiler에서 파악했던 부분들과 상당히 똑같다.. ㅋㅋㅋ
추가 GC 분석
우선 GC는 G1을 사용함. 물론 저지연 GC인 셰넌도어나 ZGC도 굉장히 훌륭하지만.. 저지연을 위해 애플리케이션 스레드랑 같이 활동하는 GC 스레드를 사용하기 때문에, 지금 JIT 컴파일 스레드 때문에 초반 부하가 감당이 안되는 상황에서는 ㅋㅋ CPU를 더 쓰느니 차라리 멈추고 실행하는 G1을 쓰는게 낫지 않을까 합니다.. 별 관측치는 없고 제 생각임..
아무튼, 현재 구조에서의 GC를 추가로 판단해볼 수 있기 때문에, 이에 대한 데이터도 보면 좋을 것 같아요.
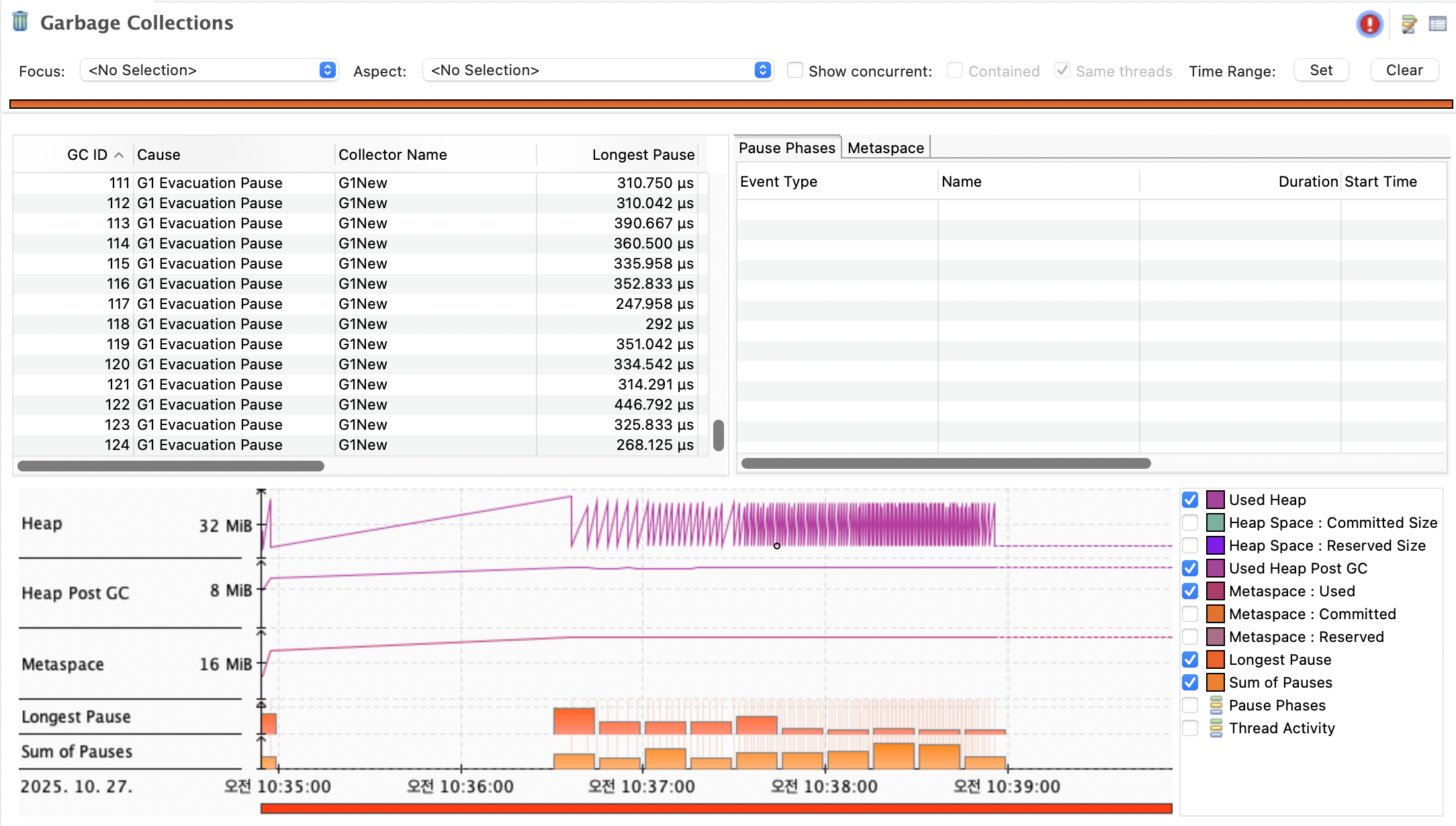
실제로 요청은 2분 30초 발생했으니 36분 30초부터 39분까지의 내역을 보면 될 것 같음. 애초에 저 구간에서 요청-응답 파이프라인이 먹통임. JIT 컴파일하느라. 그 이후부터 GC가 실제로 일을 하기 시작하는 모습인 듯 합니다. 초반에 아예 처리를 하지 않는건 아닌듯 합니다.
GC 스레드가 중후반에 저렇게 활동이 가능하려면, 해당 부분 전엔 C2 컴파일까지 종료되었을 확률이 높을 것 같다.
현재 응답을 읽어들이는 쪽에서는 "바이트 버퍼풀"을 사용하는데, 내려주는 쪽은 응답을 새로 생성함. 그리고 응답처리 부분에서 HttpRequest와 HttpResponse를 계속 만드는데, 이에 대한 쓰레기들을 줍는 것으로 예측됩니다.
해당 객체들도 전부 풀로 만들면 더 나아질 것이라 생각됨. GC 언어에서는 그나마 풀링이 메모리 주도권을 잡을 어쩌면 유일한 방법이 아닐까..
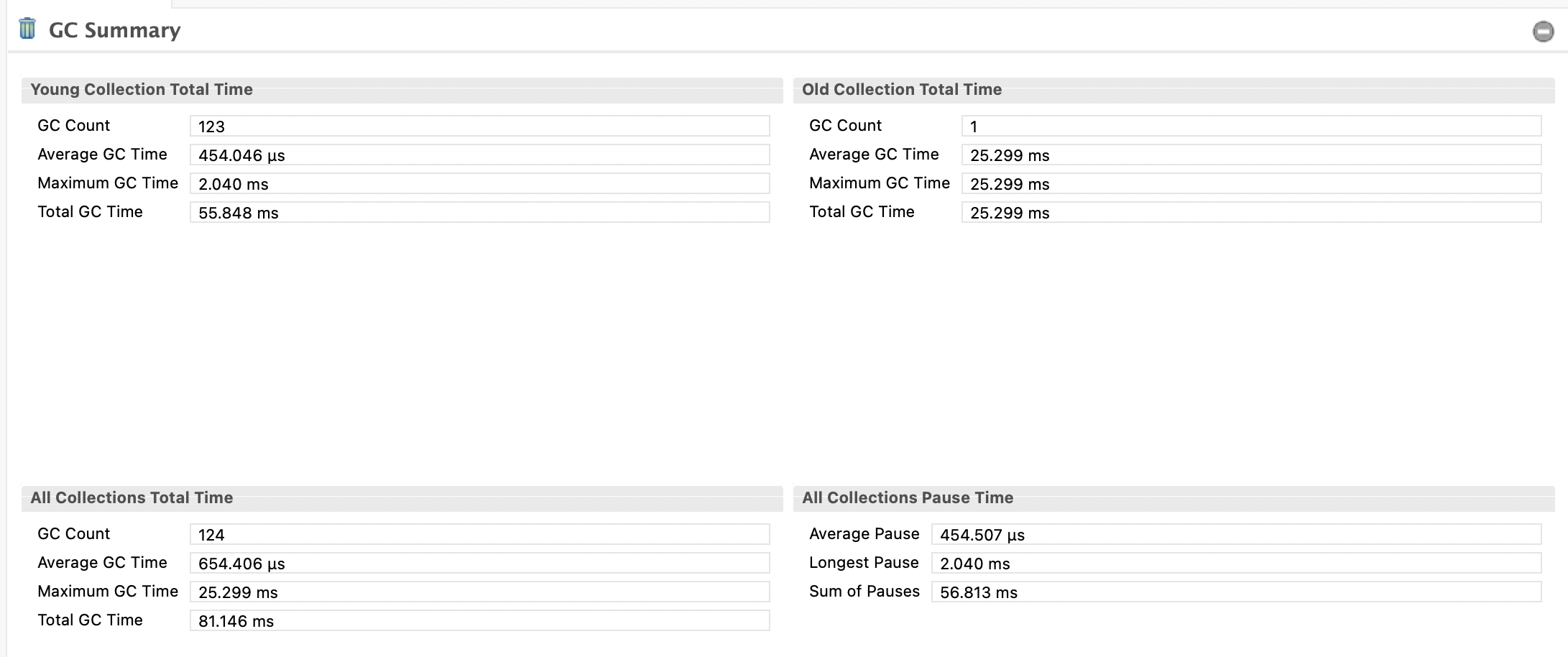
위의 이미지에서 볼 수 있겠지만 제가 측정을 잘못해서, 요청은 2분 30초정도 발생하는데, 관측은 5분했음. 감안해서 2분 30초로 계산할게요.
데이터 요약
Young Collection Total Time
- GC Count: 123 (젊은 세대 GC 실행 횟수)
- Average GC Time: 454.046 µs (평균 0.454 ms)
- Maximum GC Time: 2.040 ms (최대 GC 시간)
- Total GC Time: 55.848 ms
Old Collection Total Time
- GC Count: 1 (오래된 세대 GC 실행 횟수)
- Average GC Time: 25.299 ms
- Maximum GC Time: 25.299 ms
- Total GC Time: 25.299 ms
All Collections Total Time
- GC Count: 124 (총 GC 횟수, Young + Old)
- Average GC Time: 654.406 µs (평균 0.654 ms)
- Maximum GC Time: 25.299 ms
- Total GC Time: 81.146 ms
All Collections Pause Time
- Average Pause: 654.507 µs (평균 정지 시간)
- Longest Pause: 2.040 ms
- Sum of Pauses: 56.813 ms
분석
- 총 GC 시간 대비 실행 시간
- 총 GC 시간: 81.146 ms (0.0811초)
- 실제 사용 시간: 2분 30초 = 150초
- GC가 차지하는 비율: (81.146 / 150,000) × 100 ≈ 0.054%
이 정도는 GC 부하가 거의 없는 수준이라고 보통은 평가됩니다.
-
Young Generation GC
- 123번 실행, 평균 0.454 ms, 최대 2.040 ms, 총 55.848 ms
- 평균 GC 시간은 매우 짧고, 최대 정지 시간(2.040 ms)도 실시간 애플리케이션에서는 견딜 수 있는 범위입니다.
- 총 시간이 55.848 ms로, 150초 대비 비율은 약 **0.037%**로 무시할 만한 수준입니다.
-
Old Generation GC
- 1번 실행, 평균 및 최대 25.299 ms, 총 25.299 ms
- 오래된 세대 GC가 한 번만 발생했으며, 시간이 약 25ms로 상대적으로 길지만, 횟수가 적어 전체적인 영향은 미미합니다.
- 150초 대비 비율: (25.299 / 150,000) × 100 ≈ 0.017%
- G1의 특성상 Old GC가 거의 발생하지 않는 것은 정상적인 패턴입니다.
-
전체 정지 시간(Pause Time)
- 평균 정지: 0.654 ms, 최대 정지: 2.040 ms, 총 정지: 56.813 ms
- 최대 정지 시간 2.040 ms는 짧은 지연으로, 대화형 애플리케이션(예: 웹 서버)에서는 눈에 띄지 않을 가능성이 높습니다.
- 총 정지 시간이 56.813 ms로, 150초 대비 약 **0.0378%**로 매우 낮은 수준입니다.
-
GC 빈도
- 총 124번 GC가 150초 동안 발생했으므로, 평균 GC 간격: 150초 / 124 ≈ 1.21초
- 이는 GC가 너무 빈번하지 않고, 안정적인 주기로 동작했음을 의미합니다.
원래 더 안좋았겠지만, 최근 진행한 개선이 영향을 준 것 같음.
근데 만약 JIT 컴파일링 문제가 해결되면, 이 부분은 다시 살펴봐야함 초반부터 GC가 일어나게 될테니 지표가 더 튈 가능성이 높음.
JIT Watch 분석
이거 사용이 너무 서툴러서; 비교적 더 짧은 로그로 만들어서 사용했습니다.
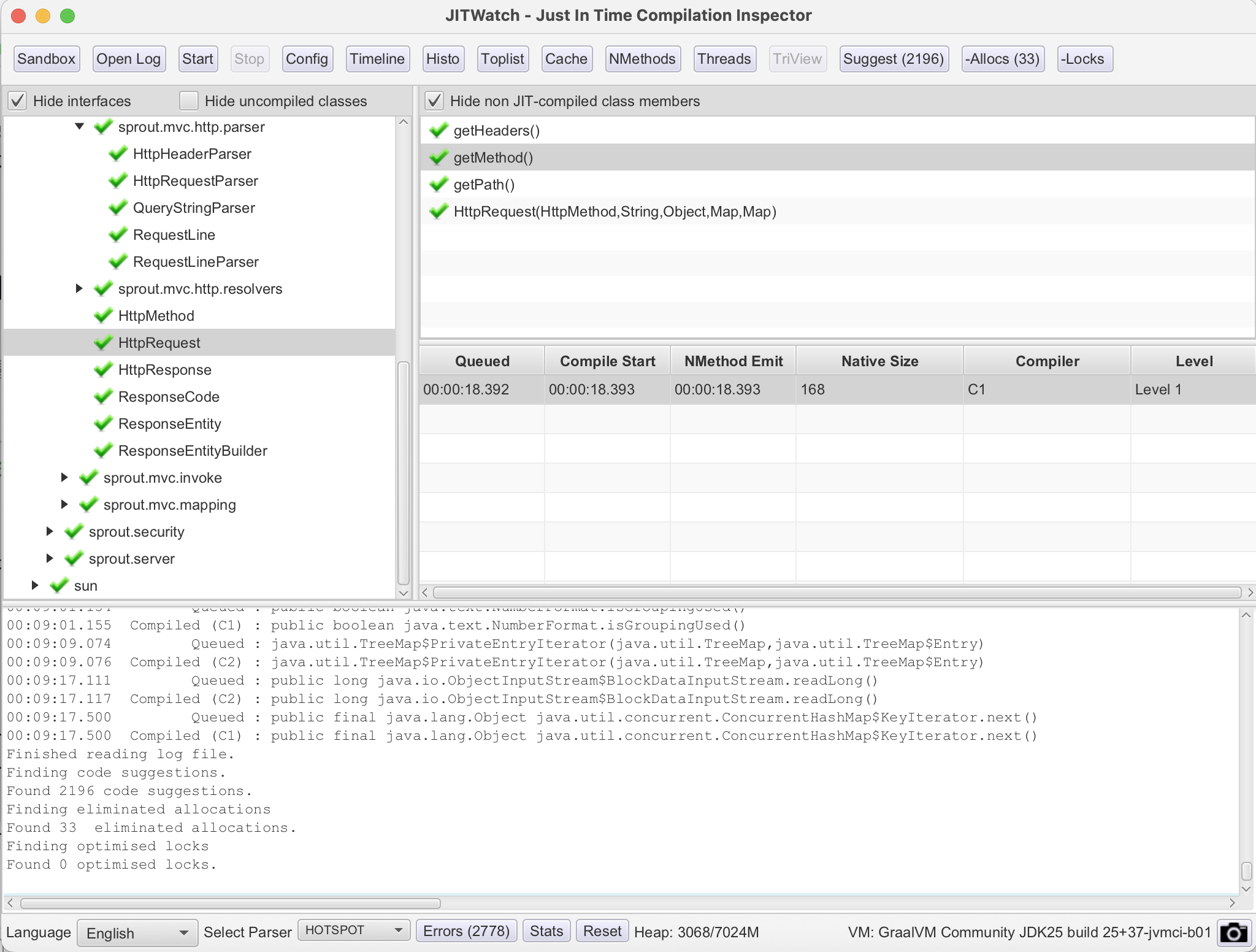
JIT Watch의 UI는 이런식이다. Open Log에서 핫스팟 로그를 열어주고, Config에서 다음과 같이 폴더를 위치시켜주면 된다.
| 항목 | 의미 | 넣어야 하는 경로 |
|---|---|---|
| Class Locations | JITWatch가 로그에 기록된 클래스(.class)를 찾아 디컴파일하거나 바이트코드 보기용으로 사용 | 컴파일 결과 폴더 (예: build/classes/java/main) 또는 .jar 파일 경로 |
| Source Locations | Java 원본 코드(.java)를 찾아 TriView 왼쪽 패널에 표시 | src/main/java 같은 소스 루트 디렉터리 |
이제 JMC에서 찾았던 병목 지점들을 확인해보자.
로그도 찾아서 넣어주고 Start를 누르면됨.
 하단에 이런 로그가 보임.
하단에 이런 로그가 보임.
Finished reading log file. Finding code suggestions. Found 2196 code suggestions. Finding eliminated allocations Found 33 eliminated allocations. Finding optimised locks Found 0 optimised locks.
HotSpot이 컴파일했거나 인라이닝을 고려했지만 최적화 여지가 있는 메서드 2,196개를 발견했다는 뜻
탈출 분석 결과, 힙 할당을 스택으로 전환해 없앤 최적화가 33번 발생함
락 제거(lock elision) 최적화는 일어나지 않음 -> 락 경쟁이 없거나, 코드가 락을 사용하지 않음 (이건 문제없다..)
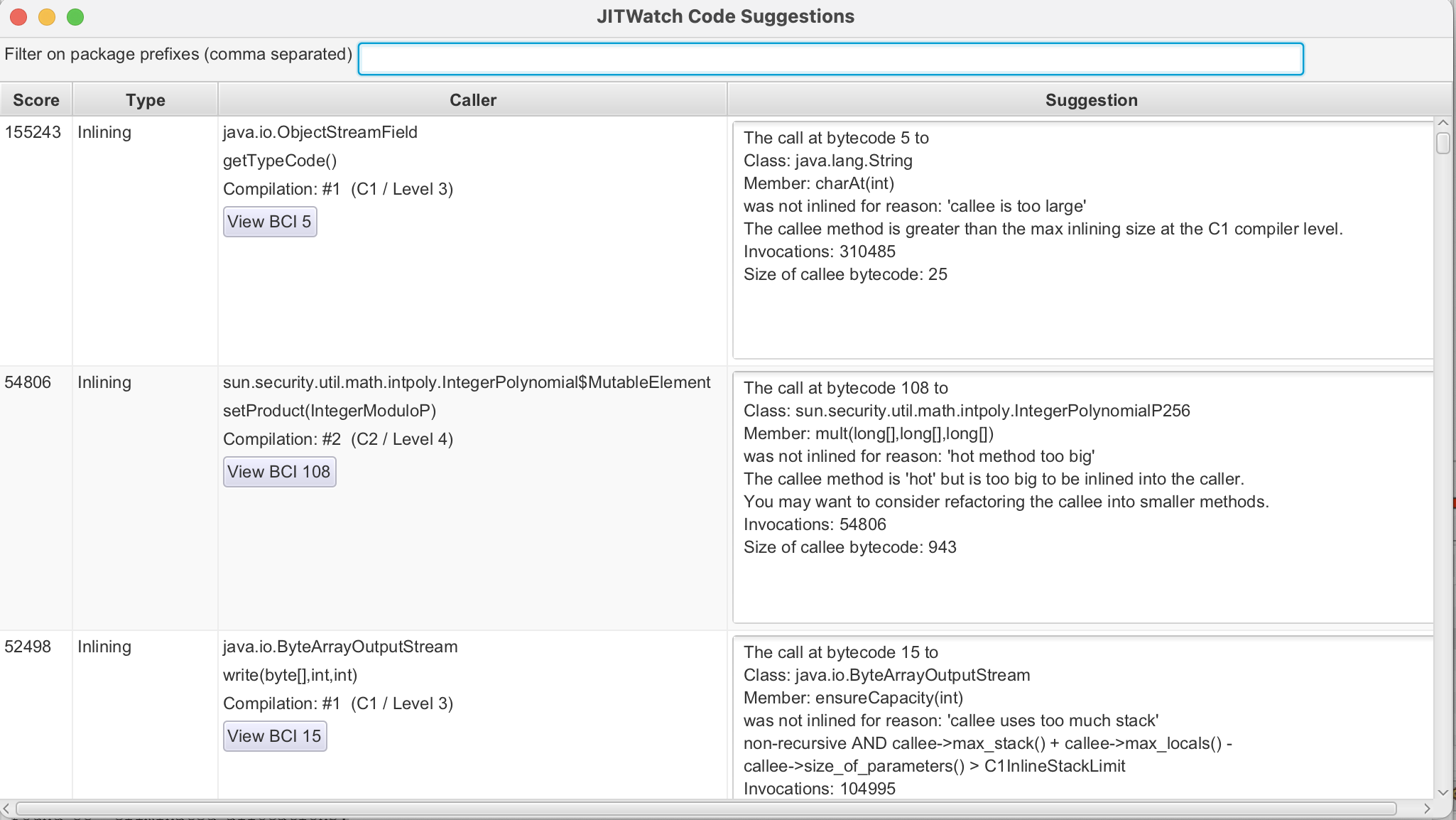 이와 같이 제안을 해준다.
이와 같이 제안을 해준다.
1. HttpUtils.readRawRequest
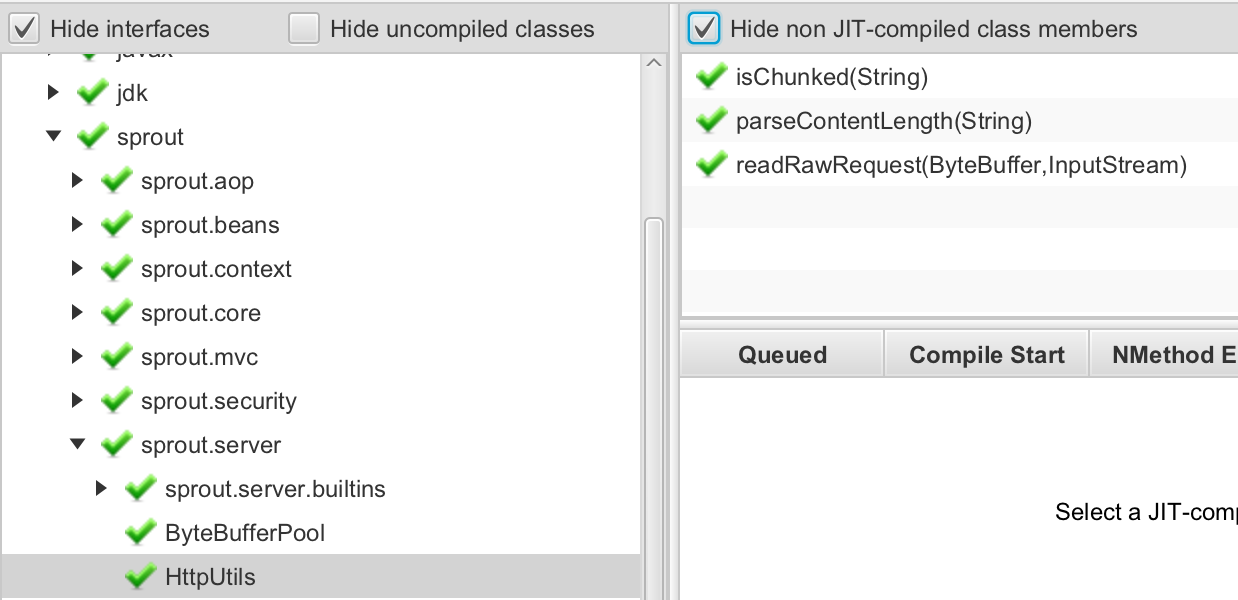 실제로 JIT 컴파일이 이루어졌다고 보여짐 ㅋㅋㅋ JMC에서 확인했던
실제로 JIT 컴파일이 이루어졌다고 보여짐 ㅋㅋㅋ JMC에서 확인했던 readRawRequest도 포함됨을 알 수 있다. 그리고 다른 메서드들도 컴파일이 되었음을 확인할 수 있다.
여기에서 상단의 TriView를 누르면 더 상세하게 확인할 수 있다.
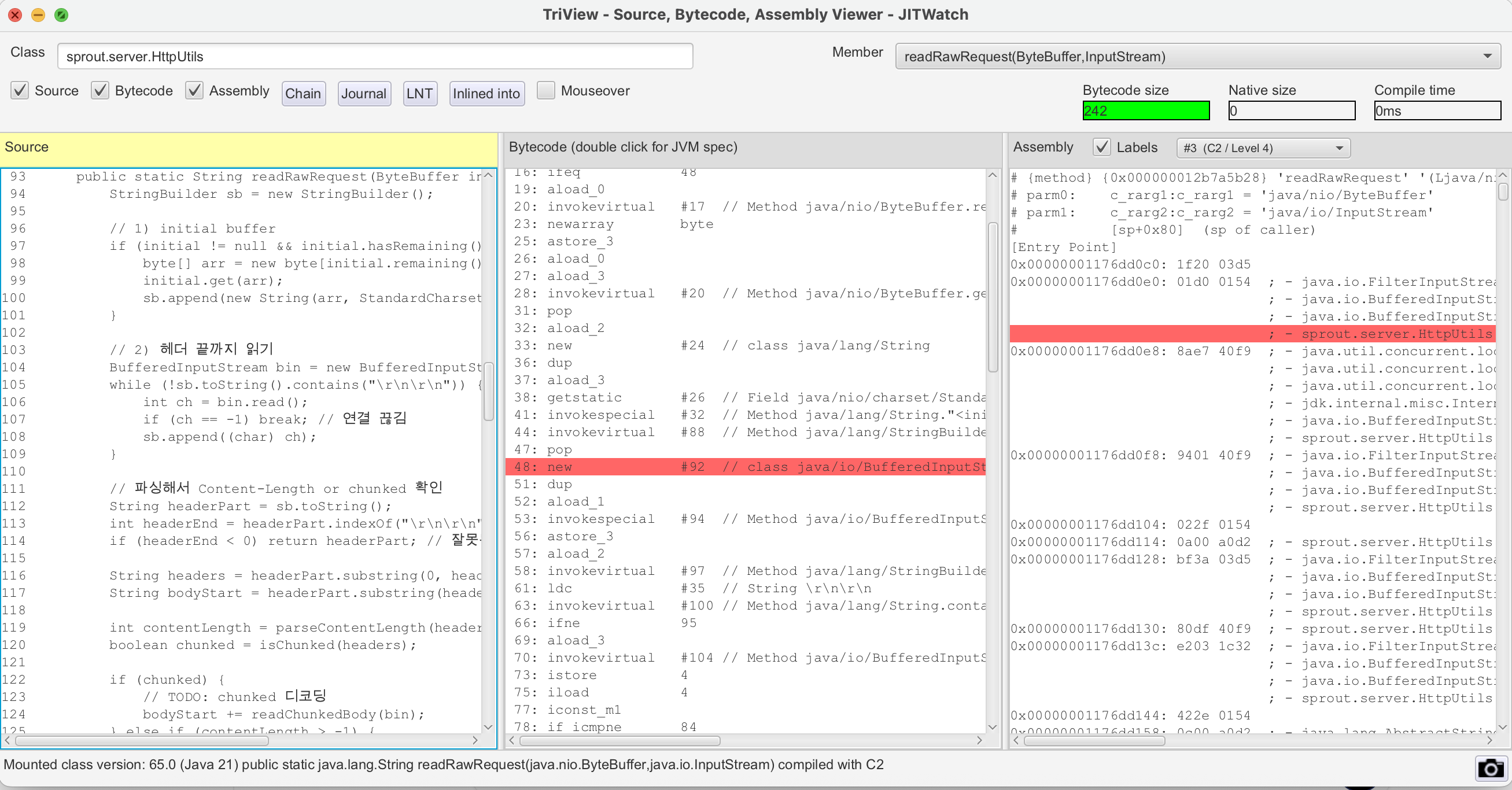 이렇게 두면 소스코드 / 자바 바이트코드 / 어셈블리까지 확인할 수 있다.
실제로 C2 컴파일까지 이루어진걸 확인할 수 있다.
이렇게 두면 소스코드 / 자바 바이트코드 / 어셈블리까지 확인할 수 있다.
실제로 C2 컴파일까지 이루어진걸 확인할 수 있다.
일단 이 부분에서 뭐라고 제안해주는지도 보자. 일단 8개 검출해줌..
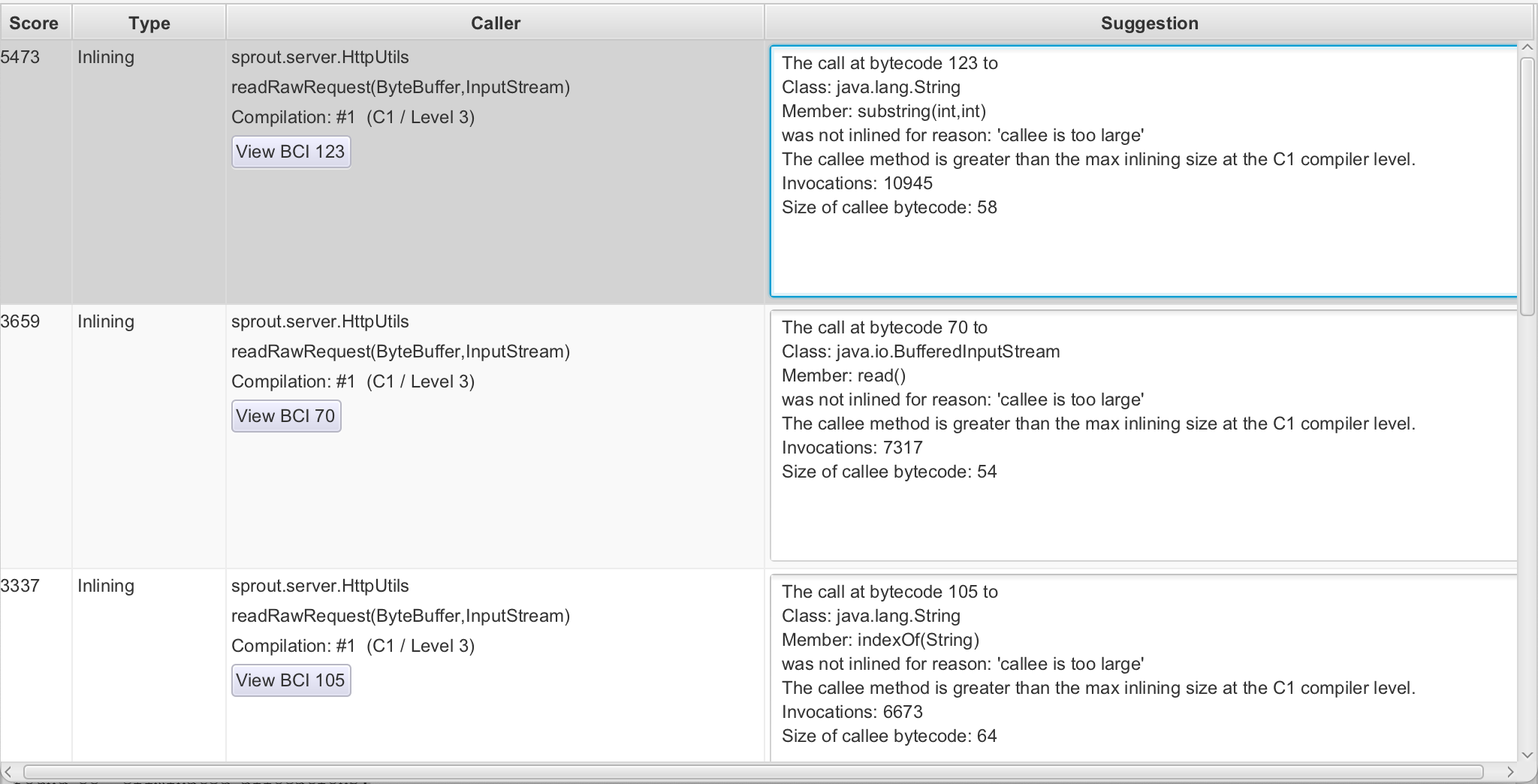 전부
전부 rawRequest 관련 제안이다.
해당 메서드에 대한 조언들을 살펴보니 다음과 같았다.
- "callee is too large"**
- 인라인 대상 메서드(=callee)의 바이트코드 크기가 C2 인라이너의 허용 한도를 넘었음(JVM의 C2 인라이닝 바이트코드 한도는 ~325 (기본값))
- 일반적으로 C2는 바이트제한으로 인라이닝을 사용함 내부상수가 있음. 이걸 증가시키는 옵션을 사용해도 좋긴함. 하지만 최대한 메서드를 쪼개는게 좋은 방법일듯 하다. 쪼개다 안되면 그땐 튜닝하는 걸로
- 해야할 것: 핫 루프 내부의 복잡한 로직을 외부로 빼기
- "unpredictable branch"
- 해당 분기문(if/else, switch 등)이 실행 중에 절반 확률로 양쪽을 번갈아 탐색함
- 이는 분기 예측을 어렵게 한다
- 실제로 6657회 관측 중 50% 확률이면 완전히 예측 불가능한 패턴이다.
- 이런 경우를 막기 위해 조기 리턴 같은 구조가 좋다.
- "callee uses too much stack"
- 인라인하려는
String(byte[], Charset)생성자의 스택 프레임 크기가 C1 인라이너 한계를 초과한 것 new String(bytes, UTF_8)을 빈번하게 생성하는 경우라면 이또한 풀링으로 재사용한다거나 해야할 것 같다
일단 이러한 코드 개선점은 받아서 리팩토링에 활용하는 것으로 하자. 이러한 부분이 당장의 메모리 할당 등에서도 효과가 있겠지만, JIT 친화적으로 코드를 작성할 경우, JIT 컴파일이 “더 빠르게”, “더 많이”, 그리고 “더 효과적으로” 일어난다
하지만 지금 코드처럼
- 분기 예측률 0.5
- 거대한 메서드(‘callee too large’)
- 스택 사용량 초과
이런 요소가 있으면 JIT이 더 프로파일링 데이터가 쌓이고 시도하려고 한다. 그래서 컴파일 자체가 지연되거나 부분 컴파일만 일어남. 코드를 더 단순화 하면 이런 "조건 충족 지연"이 사라져 초기 워밍업 (인터프리터 -> C1 -> C2) 구간이 짧아진다.
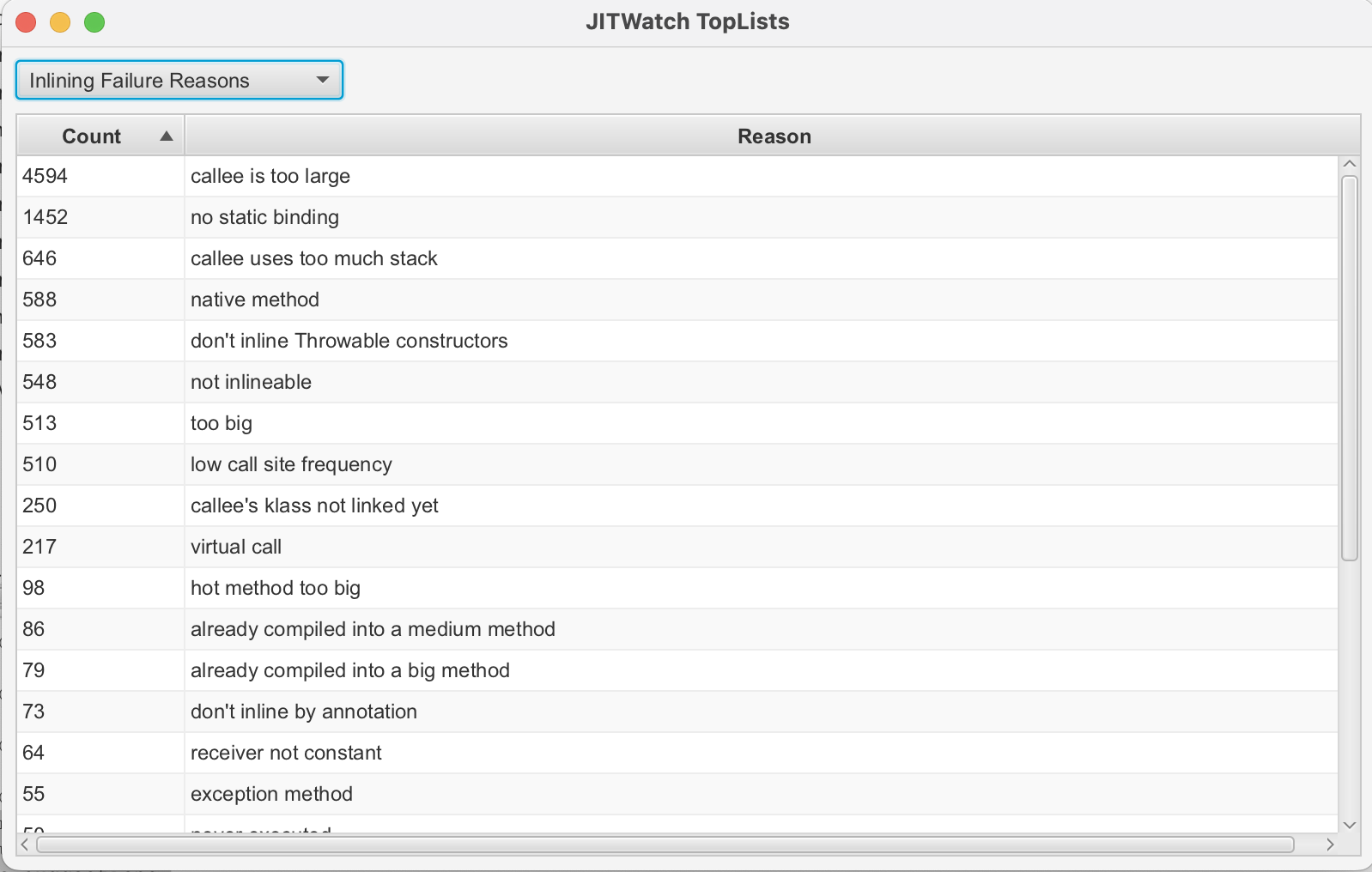
이 이미지는 대표적인 인라이닝 실패 이유들을 보여줌. 실제로 대부분의 인라이닝 실패 이유가 "너무 커서" 임
2. RequestDispatcher
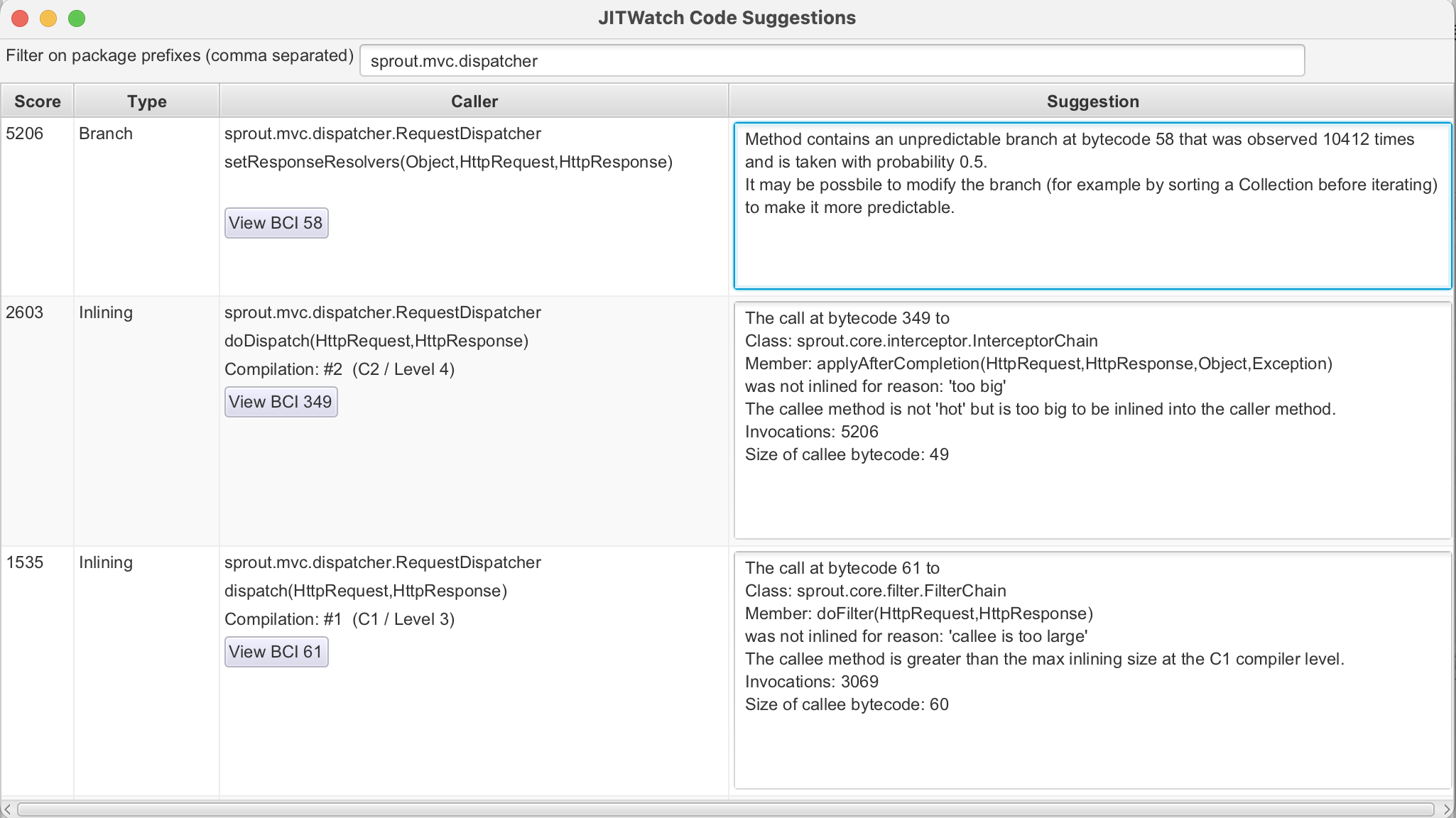
setResponseResolvers
바이트코드 58번 위치에 브랜치(조건문, 예: if-else)가 있으며,
이는 10,412번 관찰되었고 실행 확률이 50%입니다.
이는 CPU의 브랜치 예측기(Branch Predictor)가 실패할 확률이 높아 성능 저하를 초래합니다.
JVM이 예측 실패 시 파이프라인을 플러시해야 하므로 지연이 발생.
- 해당 부분은 쉽게 고칠 수 있다. 컬렉션을 미리 정렬해두면 된다.(수치가 다른건, 제가 더 짧은 로그로 재실험해서 가져왔습니다.)
doDispatch
바이트코드 349번 위치에서 InterceptorChain.applyAfterCompletion 메서드를 호출하지만,
인라이닝(메서드 코드를 호출자에 직접 삽입)되지 않았습니다.
이유는 호출 대상 메서드 크기(49바이트)가 너무 커서입니다.
인라이닝 실패 시 메서드 호출 오버헤드(스택 프레임 생성 등)가 증가.
- applyAfterCompletion 메서드를 간소화(예: 불필요한 로직 분할)를 해볼 수 있을 것 같다.
바이트코드 61번 위치에서 FilterChain.doFilter 메서드를 호출하지만, 인라이닝되지 않았습니다.
이유는 메서드 크기(60바이트)가 C1 컴파일러의 최대 인라이닝 크기를 초과했기 때문.
호출 횟수는 3,069번으로 빈번.
C1 컴파일러는 C2보다 인라이닝 기준이 엄격하다, 이는 초기 컴파일 단계에서 발생한 것이다. Tiered Compilation에서 C1 후 C2로 승격되지만, 여전히 오버헤드가 존재함.
doFilter메서드를 더 작게 분할하자
후기
다른 부분에 대해서도 추가적인 조언들이 많지만 너무 포스팅이 길어져서 여기에서 마무리 하려고 한다. 깨닫게 된건 의외로 async-profiler 정도로도 문제 원인은 대부분 동일하게 잡아낸다는 것.
JMC, JIT Watch도 너무 다루는게 서툴러서.. 좀 더 해봐야할 듯?
최대한 코드를, 특히 서버 I/O가 엮인 쪽은 코드를 JIT 친화적으로 개선해야함을 깨달았다. 객체 생성 부분에 있어서도, 최대한 재사용하는 방안으로 개선하면 좋을 것 같다. 요청객체/응답객체도 풀링하고, 메서드 쪼개고, 분기예측 쉽게 early return 으로 전반적 코드 개선이 필요할 듯? 솔직히 스칼라 대체같은거 생각하면 보기 싫어도 변수들도 오히려 정말 잘게 쪼개놓아야 하지만, 메서드 스택이 또 너무 많으면 컴파일이 어려워져서 _적절하게_해야 하는데 이게 어려울 듯
추가로 톰캣이나 네티나 Undertow 같은 곳에서는 JIT 컴파일링 문제를 안겪는지, 만약 겪는다면 어떻게 해결하는지 찾아봤는데,
톰캣에서 “10 Tips for performance tuning” 같은 문서엔 JIT 직접 언급은 적지만, JVM 옵션(-XX:+TieredCompilation, -XX:CompileThreshold, -XX:+UseJITCompilationMonitoring 등) 설정이 간접적으로 영향을 준다는 내용이 있었음.
그리고 다들 부하테스트시에는, 워밍업을 무조건 거침. JIT 특성상 어쩔수가 없는 듯 하다.
실제로 Netty 팀의 마이크로벤치마크(netty-microbench)나 CI용 성능 테스트를 보면, 항상 초반 수천~수만 번 요청을 워밍업으로 버린다.
Undertow의 벤치마크 문서나 RedHat 퍼포먼스 팀의 실험을 보면, 초반 수십 초~1분간의 워밍업을 두고 이후부터 지표를 수집한다. (일반적으로 1분 이상 워밍업을 하지 않으면 Throughput이 매 측정마다 다르게 나온다..)
그래서 운영이나 벤치마크 팀에서도 트래픽을 일부러 만들거나, 리버스 프록시에서 받은 요청을 재시도하도록 해두기도 함.
그냥 나도 내부적으로 더미 데이터를 자체적으로 보내서 자체 워밍업을 시켜버릴까 싶기도 하다.. 최근 진행한 성능 관측에서는 플랫폼 스레드(스레드 풀) 모델을 사용하지 않았지만, 스레드 풀 생성을 eager로 생성하도록 해야할듯?