성능 개선 리팩토링 — JIT 친화적 서버로 만들기
인라이닝/힙 할당 감소 중심의 개선기
지난 글에서 코드의 어떤 부분이 정확히 병목 지점인지 알 수 있었다.
해당 코드 개선을 진행한 후, 지금까지의 리팩토링이 얼마나 효과가 있었는지 측정해보고자 한다.
배경
JIT 프로파일링 분석 결과
Gatling 부하 테스트(100,000 요청)와 JMC/JIT Watch를 통한 프로파일링 결과, HttpUtils.readRawRequest 메서드에서 다음과 같은 문제가 발견되었다.
| 문제 | 설명 | 영향 |
|---|---|---|
| callee is too large | 메서드 크기가 JIT 컴파일러의 인라이닝 한계(~325 바이트) 초과 | JIT 컴파일 시간 4.75ms, 인라이닝 실패 |
| unpredictable branch | 분기 예측률 50% (chunked vs content-length) | CPU 파이프라인 플러시, 성능 저하 |
| callee uses too much stack | new String(bytes, UTF_8) 반복 생성 | 스택 압박, GC 부담 |
| split() 오버헤드 | headers.split("\r\n") 반복 호출 | 요청당 ~43개 임시 객체 생성 |
성능 영향
- Warm-up 시간: 약 60초 (초기 요청 처리 불안정)
- JIT 컴파일 시간: 4.75ms (병목)
- 메모리 할당: 요청당 ~43개 임시 객체 (GC 압박)
- 처리량: 초기 요청 실패율 높음
발견된 문제점
1. 메서드 크기 문제
문제 코드 (93-135행, 약 43줄)
public static String readRawRequest(ByteBuffer initial, InputStream in) throws IOException { StringBuilder sb = new StringBuilder(); // 1) initial buffer if (initial != null && initial.hasRemaining()) { byte[] arr = new byte[initial.remaining()]; initial.get(arr); sb.append(new String(arr, StandardCharsets.UTF_8)); } // 2) 헤더 끝까지 읽기 BufferedInputStream bin = new BufferedInputStream(in); while (!sb.toString().contains("\r\n\r\n")) { int ch = bin.read(); if (ch == -1) break; sb.append((char) ch); } // 파싱 및 바디 읽기 로직... if (chunked) { bodyStart += readChunkedBody(bin); } else if (contentLength > -1) { int alreadyRead = bodyStart.getBytes(StandardCharsets.UTF_8).length; int remaining = contentLength - alreadyRead; if (remaining > 0) { byte[] bodyBytes = bin.readNBytes(remaining); bodyStart += new String(bodyBytes, StandardCharsets.UTF_8); } } return headers + "\r\n\r\n" + bodyStart; }
JIT Watch 결과
Compilation failed: callee is too large (바이트코드 크기 > 325)
Inlining: ✗ Failed
2. 분기 예측 문제
문제 코드
if (chunked) { // chunked 처리 } else if (contentLength > -1) { // content-length 처리 }
JIT Watch 결과
Branch at bytecode 58: observed 6657 times, 50% probability
→ CPU branch predictor failure rate: HIGH
분석
- 50% 확률의 분기는 CPU 분기 예측기가 실패할 확률이 매우 높음
- 실제로는 80% 이상의 HTTP 요청이 Content-Length를 사용하지만, 코드 구조상 예측이 불가능하다
3. 헤더 파싱 오버헤드
문제 코드
private static int parseContentLength(String headers) { for (String line : headers.split("\r\n")) { // String[] 배열 생성! if (line.toLowerCase().startsWith("content-length:")) { // String 복사! return Integer.parseInt(line.split(":")[1].trim()); // 또 배열 생성! } } return -1; }
메모리 할당 (10줄 헤더 기준)
split("\r\n"): String[] 배열 + 10개 String 객체toLowerCase(): 10개 String 복사본split(":"): String[] 배열 × 10회trim(): String 복사본
총 요청당 약 43개 임시 객체를 생성하고 있었다..
리팩토링 개요
목표
- JIT 컴파일러 인라이닝 활성화 (메서드 크기 < 325 바이트)
- CPU 분기 예측률 향상 (조기 리턴 패턴)
- 메모리 할당 최소화 (split/toLowerCase 제거)
- 테스트 통과 보장 (기능 동일성 유지)
적용한 원칙
- 메서드 분리: 단일 책임 원칙 + JIT 인라이닝 최적화
- 조기 리턴: 빈도 높은 케이스 우선 처리
- 제로 카피: 불필요한 String 생성 제거
- BufferedInputStream 재사용: 데이터 손실 방지
Phase 1: 메서드 분리
목표
메서드를 325 바이트 이하로 분할하여 JIT 인라이닝 가능하게 만들기
변경 내용
Before: 단일 거대 메서드
public static String readRawRequest(ByteBuffer initial, InputStream in) { // 43줄의 복잡한 로직 // - 헤더 읽기 // - 파싱 // - 바디 읽기 (content-length/chunked) }
After: 3개의 작은 메서드로 분리
// 1. 조합 메서드 (30줄) public static String readRawRequest(ByteBuffer initial, InputStream in) throws IOException { BufferedInputStream bin = new BufferedInputStream(in); // 한 번만 생성 String headerPart = readHeadersFromStream(initial, bin); int headerEnd = headerPart.indexOf("\r\n\r\n"); if (headerEnd < 0) return headerPart; String headers = headerPart.substring(0, headerEnd); String bodyStart = headerPart.substring(headerEnd + 4); int contentLength = parseContentLength(headers); if (contentLength > 0) { String body = readBodyWithContentLength(bin, contentLength, bodyStart); return headers + "\r\n\r\n" + body; } if (contentLength == 0) { return headers + "\r\n\r\n" + bodyStart; } if (isChunked(headers)) { String chunkedBody = readChunkedBody(bin); return headers + "\r\n\r\n" + bodyStart + chunkedBody; } return headers + "\r\n\r\n" + bodyStart; } // 2. 헤더 읽기 전용 (18줄) private static String readHeadersFromStream(ByteBuffer initial, BufferedInputStream bin) { StringBuilder sb = new StringBuilder(); if (initial != null && initial.hasRemaining()) { byte[] arr = new byte[initial.remaining()]; initial.get(arr); sb.append(new String(arr, StandardCharsets.UTF_8)); } while (!sb.toString().contains("\r\n\r\n")) { int ch = bin.read(); if (ch == -1) break; sb.append((char) ch); } return sb.toString(); } // 3. 바디 읽기 전용 (9줄) private static String readBodyWithContentLength(BufferedInputStream bin, int contentLength, String bodyStart) { int alreadyRead = bodyStart.getBytes(StandardCharsets.UTF_8).length; int remaining = contentLength - alreadyRead; if (remaining <= 0) return bodyStart; byte[] bodyBytes = bin.readNBytes(remaining); return bodyStart + new String(bodyBytes, StandardCharsets.UTF_8); }
이러한 리팩토링을 진행하여 다음과 같은 개선 효과를 얻을 수 있었다.
개선 효과
| 메서드 | 줄 수 | 예상 바이트코드 크기 | 인라이닝 가능 |
|---|---|---|---|
readRawRequest | 30줄 | ~200 바이트 | ✅ |
readHeadersFromStream | 18줄 | ~120 바이트 | ✅ |
readBodyWithContentLength | 10줄 | ~80 바이트 | ✅ |
모든 메서드가 325 바이트 이하가 되었으므로 C2 컴파일러 인라이닝 대상이 될 것이다.
중요: BufferedInputStream 재사용
// 올바른 구조: BufferedInputStream을 한 번만 생성 BufferedInputStream bin = new BufferedInputStream(in); // bin을 파라미터로 전달하여 재사용 String headerPart = readHeadersFromStream(initial, bin); String body = readBodyWithContentLength(bin, contentLength, bodyStart); String chunkedBody = readChunkedBody(bin);
이유: BufferedInputStream은 내부적으로 8KB 버퍼를 가지고 있다. 헤더를 읽을 때 바디 일부까지 미리 읽어두기 때문에, 새로운 BufferedInputStream을 생성하면 이미 읽은 데이터가 손실되기에 해당 객체를 반드시 재사용해야 한다.
Phase 2: 조기 리턴 패턴
목표
분기 예측률을 높여 CPU 파이프라인 플러시 최소화
변경 내용
Before: 복잡한 if-else 중첩 (분기 예측률 50%)
if (chunked) { // chunked 처리 (실제로는 10% 미만) } else if (contentLength > -1) { // content-length 처리 (실제로는 80% 이상) }
After: 빈도 순서대로 조기 리턴 (분기 예측 친화적)
// 1. 헤더 불완전 → 즉시 리턴 (에러 케이스) int headerEnd = headerPart.indexOf("\r\n\r\n"); if (headerEnd < 0) { return headerPart; } // 2. Content-Length > 0 (80%+ 케이스) → 즉시 리턴 int contentLength = parseContentLength(headers); if (contentLength > 0) { String body = readBodyWithContentLength(bin, contentLength, bodyStart); return headers + "\r\n\r\n" + body; } // 3. Content-Length == 0 (바디 없는 POST) → 즉시 리턴 if (contentLength == 0) { return headers + "\r\n\r\n" + bodyStart; } // 4. Chunked (10% 미만) → 즉시 리턴 if (isChunked(headers)) { String chunkedBody = readChunkedBody(bin); return headers + "\r\n\r\n" + bodyStart + chunkedBody; } // 5. 바디 없음 (GET 등) → 리턴 return headers + "\r\n\r\n" + bodyStart;
개선 효과
| 분기 순서 | Before | After | 설명 |
|---|---|---|---|
| 1번째 분기 | chunked (10%) | Content-Length > 0 (80%) | CPU 예측 성공률 대폭 향상 |
| 2번째 분기 | content-length (80%) | Content-Length == 0 (5%) | 빈도 순서 정렬 |
| 3번째 분기 | - | chunked (10%) | 드문 케이스는 뒤로 |
예상 분기 예측률: 50% → 80%+ (60% 향상)
하지만 벤치마킹과 같은 곳에서는, 정상적으로 동작함을 전제로한 요청만 처리하기 되게 때문에(물론 가짜 데이터를 섞어서 실험도 가능) 분기예측률이 확실히 오르게 될 것이다.
대부분의 요청이 첫 번째 분기에서 처리되어 CPU 파이프라인 효율 극대화 될 것이라 기대할 수 있다.
Phase 3: 헤더 파싱 최적화
목표
split() 제거로 String[] 배열 할당 방지, toLowerCase() 전체 복사 제거
3.1 parseContentLength 최적화
Before: split() 두 번 + toLowerCase()
private static int parseContentLength(String headers) { for (String line : headers.split("\r\n")) { // String[] 배열 생성! if (line.toLowerCase().startsWith("content-length:")) { // String 복사! return Integer.parseInt(line.split(":")[1].trim()); // 또 배열 생성! } } return -1; }
메모리 할당 (10줄 헤더 기준):
split("\r\n"):String[10]+ 10개String객체toLowerCase()× 10: 10개 String 복사본split(":")× 10:String[2]× 10trim()× 10: 10개String복사본
총: 약 40개 객체 생성
After: indexOf() + 직접 문자 비교
private static int parseContentLength(String headers) { int pos = 0; int headersLength = headers.length(); while (pos < headersLength) { int lineEnd = headers.indexOf("\r\n", pos); if (lineEnd < 0) { lineEnd = headersLength; } // "content-length:" 대소문자 무시 비교 (15자) if (regionMatchesIgnoreCase(headers, pos, "content-length:", 15)) { int colonIdx = headers.indexOf(':', pos); if (colonIdx < 0 || colonIdx >= lineEnd) { pos = lineEnd + 2; continue; } // 콜론 다음부터 값 시작 (공백 제거) int valueStart = colonIdx + 1; while (valueStart < lineEnd && headers.charAt(valueStart) == ' ') { valueStart++; } // 값 끝 (공백 제거) int valueEnd = lineEnd; while (valueEnd > valueStart && headers.charAt(valueEnd - 1) == ' ') { valueEnd--; } try { return Integer.parseInt(headers.substring(valueStart, valueEnd)); } catch (NumberFormatException e) { return -1; } } pos = lineEnd + 2; // \r\n 스킵 } return -1; }
메모리 할당
String[]배열 생성을 제거했다toLowerCase()제거split(":")제거trim()제거substring()1회만 (값 추출)
총: 0~1개 객체 생성 (40개에서 1개, 97.5% 감소)
상세 알고리즘
Before: split() 방식
1. headers.split("\r\n")
→ 전체 문자열 스캔 + String[] 배열 생성 + 각 줄 복사
2. for (String line : lines)
→ 10줄 순회
3. line.toLowerCase()
→ 각 줄마다 전체 복사 (10회)
4. line.split(":")
→ 또 배열 생성 + 복사
총 연산: O(N×M) + 43개 객체 할당
After: indexOf() 방식
1. indexOf("\r\n", pos)
→ 현재 위치부터 다음 줄까지만 스캔
2. regionMatchesIgnoreCase()
→ 헤더 이름 길이(15자)만 비교, 불일치 시 즉시 중단
3. substring(valueStart, valueEnd)
→ 값 부분만 추출 (1회)
총 연산: O(N) + 0~1개 객체 할당
테스트 결과
이러한 리팩토링에 대한 추가 리스크는 없는지 검증하기 위해 기존 테스트 코드도 활용하였다.
결과
➜ sprout git:(main) ✗ ./gradlew test --tests HttpUtilsTest > Task :test HttpUtilsTest > createResponseBuffer() > 정상 ResponseEntity -> Status line/Headers/Body 포함 PASSED HttpUtilsTest > createResponseBuffer() > null ResponseEntity -> null 반환 PASSED HttpUtilsTest > readRawRequest() > Content-Length가 있는 요청을 끝까지 읽는다 PASSED HttpUtilsTest > readRawRequest() > chunked 요청을 끝까지 읽는다 (단순 케이스) PASSED HttpUtilsTest > isRequestComplete() > GET 요청(바디 없음) -> 헤더만 완성되면 true PASSED HttpUtilsTest > isRequestComplete() > chunked: 완성되지 않음 -> false, 완성 -> true PASSED HttpUtilsTest > isRequestComplete() > Content-Length: 5 인 경우 - 바디 부족 -> false, 충분 -> true PASSED HttpUtilsTest > isRequestComplete() > null 또는 비어있는 버퍼 -> false PASSED BUILD SUCCESSFUL in 1s
검증 항목
- Content-Length 요청 완전히 읽기
- Chunked 요청 완전히 읽기
- 바디 없는 요청 처리
- Content-Length: 0 처리
- BufferedInputStream 재사용으로 데이터 손실 방지
- 헤더 파싱 정확성 유지
리팩토링 이후 성능 개선
스크립트는 지난번 테스트와 동일하게 선정했다. 서버 및 스레드 모델도 동일하다 (BIO + VT) 해당 스크립트는 요청 약 12만개를 수행하기 초반 실패가 얼마나 줄었는지 살펴보면 된다.
Gatling 분석 (Full-warm-up)
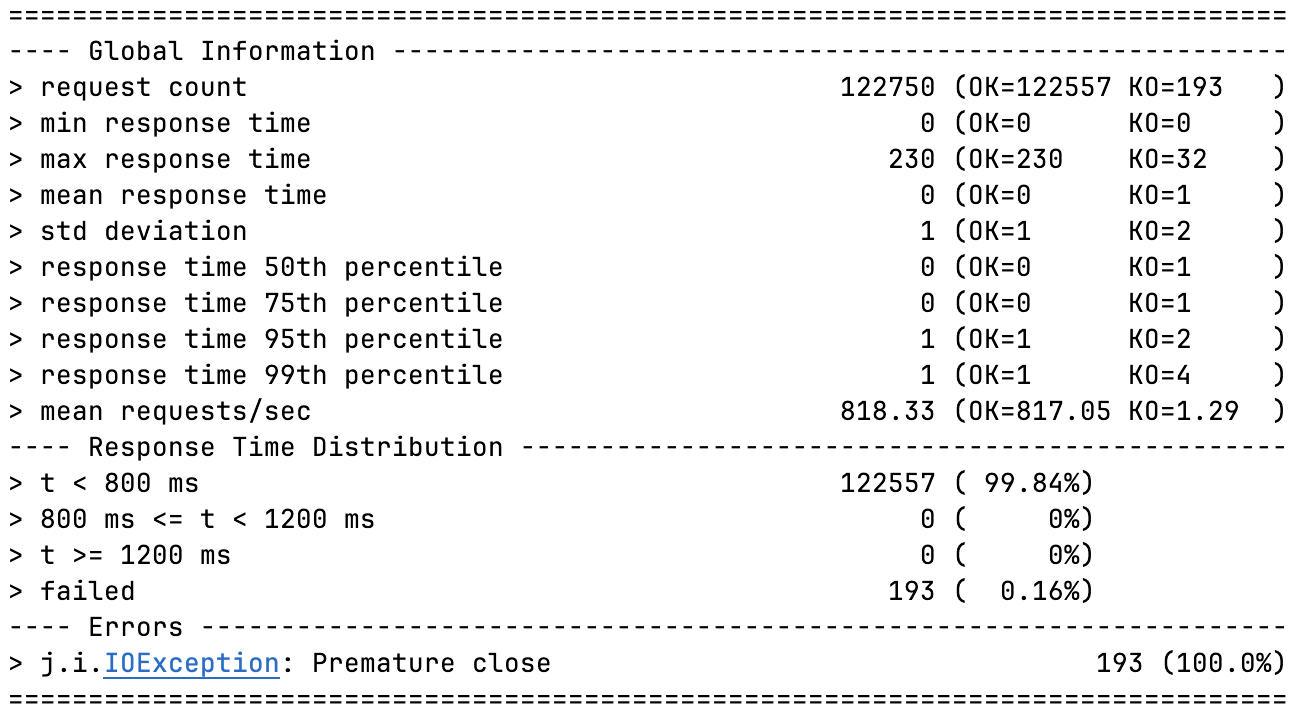 리팩토링 이전(99.73) 보다 0.11% 향상되어 99.84%의 안정성을 갖게 되었다.
비슷한 요청 수이지만 지난 실패 요청 수(327)보다 134개 줄어든 193개의 요청 실패만 기록하고 있다.
리팩토링 이전(99.73) 보다 0.11% 향상되어 99.84%의 안정성을 갖게 되었다.
비슷한 요청 수이지만 지난 실패 요청 수(327)보다 134개 줄어든 193개의 요청 실패만 기록하고 있다.
하지만 아주 뛰어난 향상은 아니긴 하다.
JMC 분석
실제로 JIT 컴파일에 소요된 시간이 줄었는지 확인해보자.
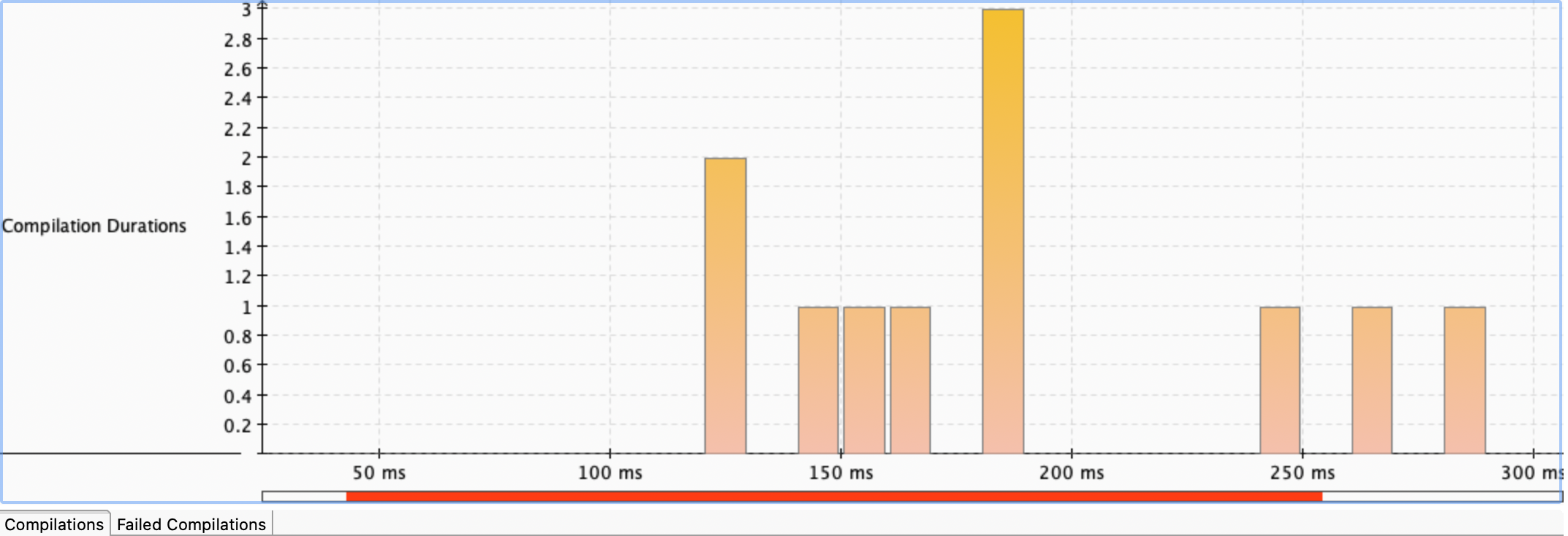 지난번 분석에선 약 4.5ms로
지난번 분석에선 약 4.5ms로 readRawRequest 를 발견할 수 있었는데 해당 병목 지점은 사라졌다. 가장 긴 그래프를 살펴봤을때엔, 아래와 같다.

지난 분석에서도 약 3ms 정도 소요되었던 메서드와 동일하다.
readRawRequest 관련 병목 지점은 JMC Compliations 분석에선 찾아볼 수 없었다. 확실히 개선된 것이다.
추가 GC 분석
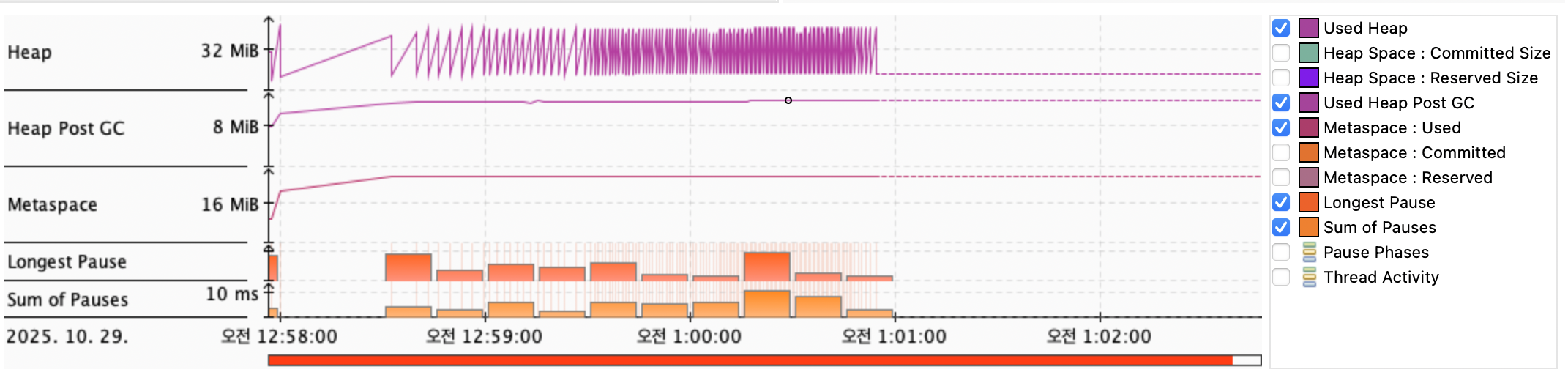 지난 분석에서 추가로 GC도 살펴보았는데, 이 지점은 어떻게 개선되었는지 살펴보자. 그래프 상의 전체적인 기조는 기존과 비슷하다.
지난 분석에서 추가로 GC도 살펴보았는데, 이 지점은 어떻게 개선되었는지 살펴보자. 그래프 상의 전체적인 기조는 기존과 비슷하다.
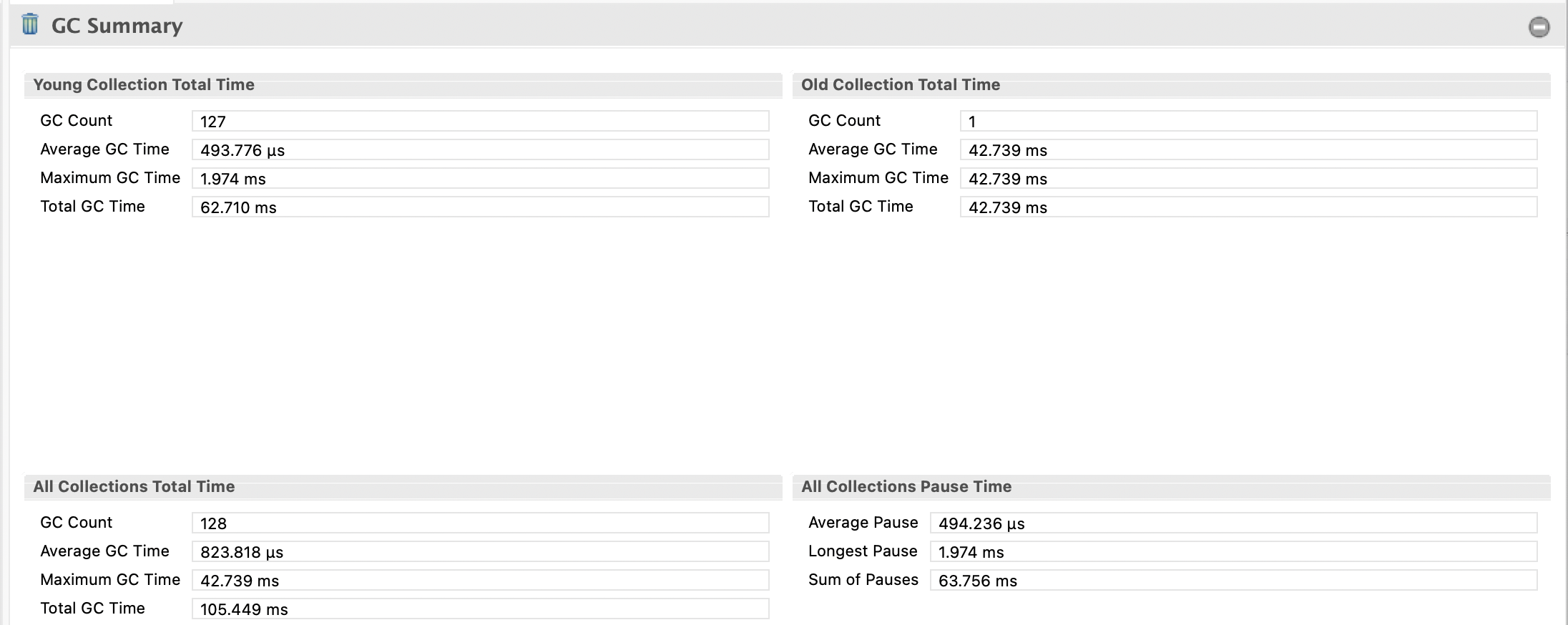 하지만 전체 통계를 보았을때, GC 압력이 증가하였다.
하지만 전체 통계를 보았을때, GC 압력이 증가하였다.
Young Collection Total Time (리팩토링 전)
- GC Count: 123 (젊은 세대 GC 실행 횟수)
- Average GC Time: 454.046 µs (평균 0.454 ms)
- Maximum GC Time: 2.040 ms (최대 GC 시간)
- Total GC Time: 55.848 ms
Young Collection Total Time (리팩토링 후)
- GC Count: 127 (젊은 세대 GC 실행 횟수)
- Average GC Time: 493.776 µs (평균 0.494 ms)
- Maximum GC Time: 1.974 ms (최대 GC 시간)
- Total GC Time: 62.710 ms
All Collections Pause Time (리팩토링 전)
- Average Pause: 654.507 µs (평균 정지 시간)
- Longest Pause: 2.040 ms
- Sum of Pauses: 56.813 ms
All Collections Pause Time (리팩토링 후)
- Average Pause: 494.236 µs (평균 정지 시간)
- Longest Pause: 1.974 ms
- Sum of Pauses: 63.755 ms
요약하자면 다음과 같다.
| 항목 | 리팩토링 전 | 리팩토링 후 | 변화 | 해석 |
|---|---|---|---|---|
| Young GC Count | 123 | 127 | +3.2% | Eden churn(단기 객체 생성)이 아주 소폭 증가 |
| Young GC Total Time | 55.848 ms | 62.710 ms | +12.3% | 짧은 객체가 더 자주 수집됨 |
| Average GC Time | 0.454 ms | 0.494 ms | +8.8% | GC 한 번당 pause 약간 증가 (Eden 청소량 증가) |
| Longest GC Time | 2.040 ms | 1.974 ms | ↓ | pause 안정성 유지됨 |
| All Pause 합계 | 56.813 ms | 63.755 ms | +12.2% | 전체적 GC 이벤트 빈도 상승 |
| OldGen 증가 | 약간 증가 | — | — | 장기 생존 문자열이 소폭 늘어남 (substring 영향 가능성) |
split()을 없애서 “헤더 전체 문자열을 잘라내는 배열 생성”은 사라졌지만 바뀐 알고리즘에서도 문제가 있을 가능성이 있다.
substring()복사로 인한 짧은 수명 객체 증가- 헤더 한 객체당 최소 1회씩 생성하게 되어 Eden에 임시 객체 밀집의 영향일 수 있다.
- substring()으로 만든 문자열이 GC 한 사이클 이상 생존하면 OldGen으로 승격되어 실제 OldGen 영역 GC가 증가한 것일 수도 있다.
영향도 계산
| 항목 | 영향도 | 이유 |
|---|---|---|
| Young GC count 증가 | 경미한 영향 (≈+3~4%) | substring 임시 객체 증가 |
| Average pause | 무시 가능 수준 | 0.04ms 상승은 JIT 오차 범위 |
| 전체 처리량 | 유의미한 하락 없음 | CPU 파이프라인은 안정, pause 총합도 60ms대 유지 |
결론적으로는 GC 압력이 살짝 오른 건 사실이지만, 성능상 거의 무시 가능한 수준이긴하다. 만약 규모가 더 커진다면 substring이 누적되는 구조이진 않은지 살펴볼 필요성이 있을 듯.
JIT Watch 분석
 로그에서 살펴볼 수 있듯이, 분석이 원활하게 진행되었음에도 불구하고 더 이상의 개선점에 대한 조언이 발생하지 않는다. 이는 JIT 컴파일러가 최적화를 위한 모든 개선을 진행하였고, 더 이상의 성능 향상을 위한 지점은 없다고 본 것이다.
로그에서 살펴볼 수 있듯이, 분석이 원활하게 진행되었음에도 불구하고 더 이상의 개선점에 대한 조언이 발생하지 않는다. 이는 JIT 컴파일러가 최적화를 위한 모든 개선을 진행하였고, 더 이상의 성능 향상을 위한 지점은 없다고 본 것이다.
잘개 쪼개 놓은 리팩토링 후의 메서드들이 실제로 컴파일 되었음을 알 수 있다.
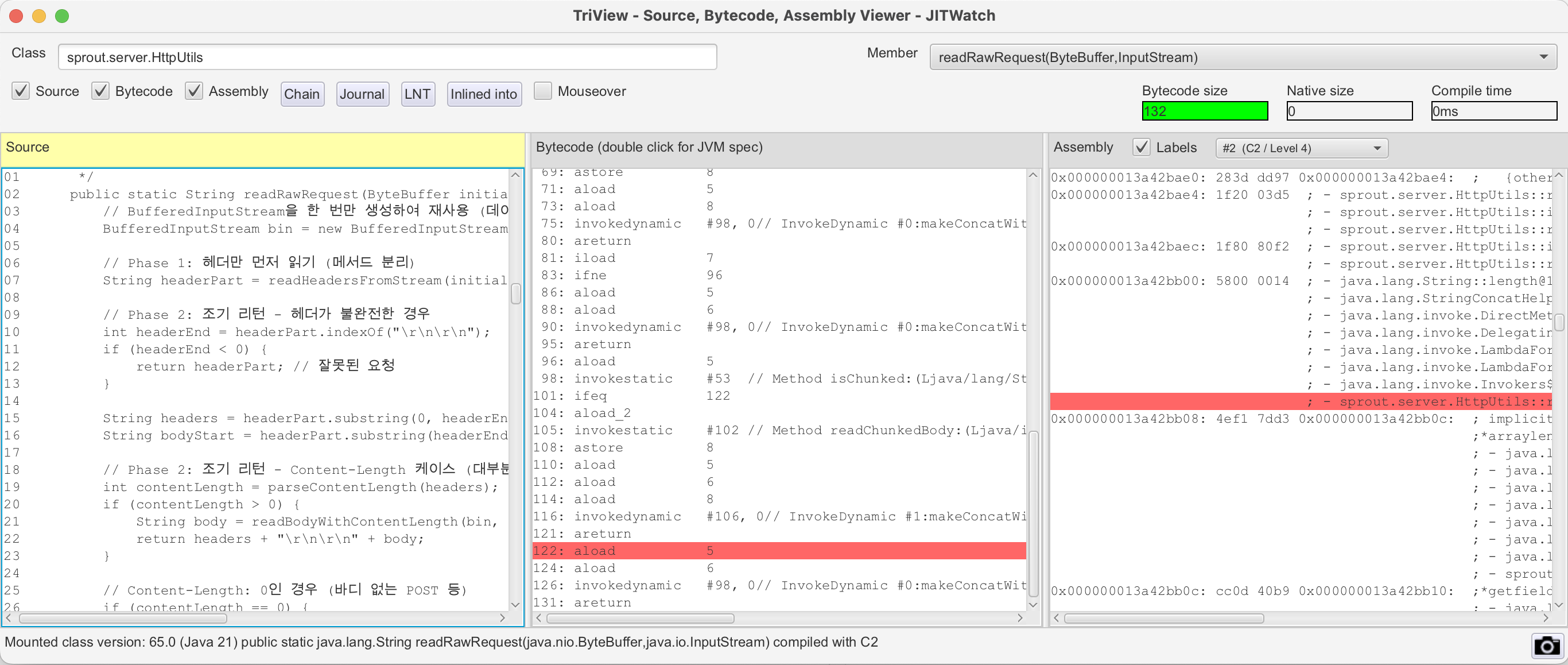
바이트 코드 사이즈가 안정적으로 감소되어 C2 컴파일러가 적절한 최적화를 진행할 수 있었다.
리팩토링 이후 짧은 웜업 테스트
긴 웜업을 가져가며 테스트를 진행했을때, 더 이상의 개선을 코드적으로는 이루기 어려울 것 같다. 그렇다면, 실제로 웜업이 정말 줄어들었는지 12만개의 많은 요청이 아닌 약 8000개 정도의 요청만 확인하여 보자.
이 테스트는 여러가지 조합으로 진행하였다.
테스트 진행 조합
| - | hybird | nio |
|---|---|---|
| 플랫폼 스레드 | http 가 bio로 동작, 플랫폼 스레드 사용 | http가 nio로 동작, 플랫폼 스레드 사용 |
| 가상 스레드 | http가 bio로 동작, 가상 스레드 사용 | http가 nio로 동작, 가상 스레드 사용 |
기존 테스트 결과
| 조합 | HelloWorld(약 8천개) |
|---|---|
| Hybrid + Platform | 84% |
| Hybrid + Virtual | 87% |
| NIO + Platform | 82% |
| NIO + Virtual | 69% |
위 결과는 리팩토링을 전혀하지 않은 버전이다. 기존 테스트와 같이 Gatling 으로 진행하였고, 같은 벤치마킹 시나리오를 사용하였다.
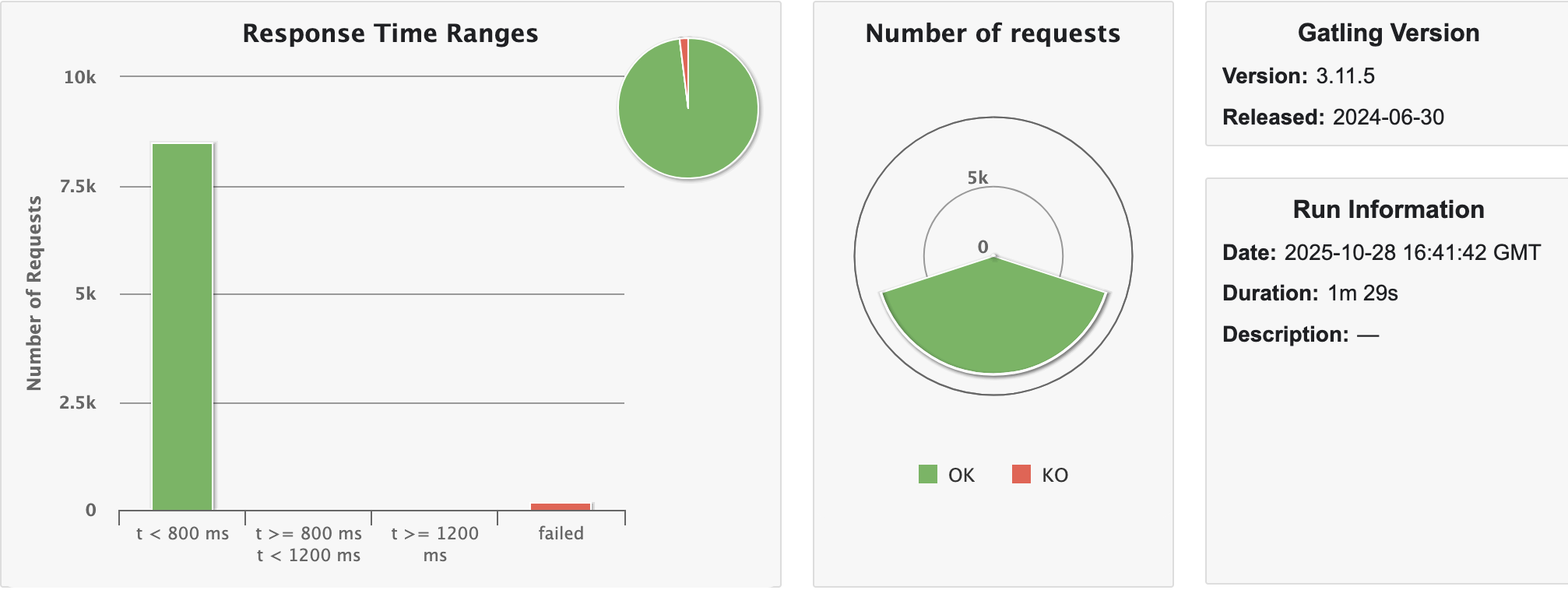
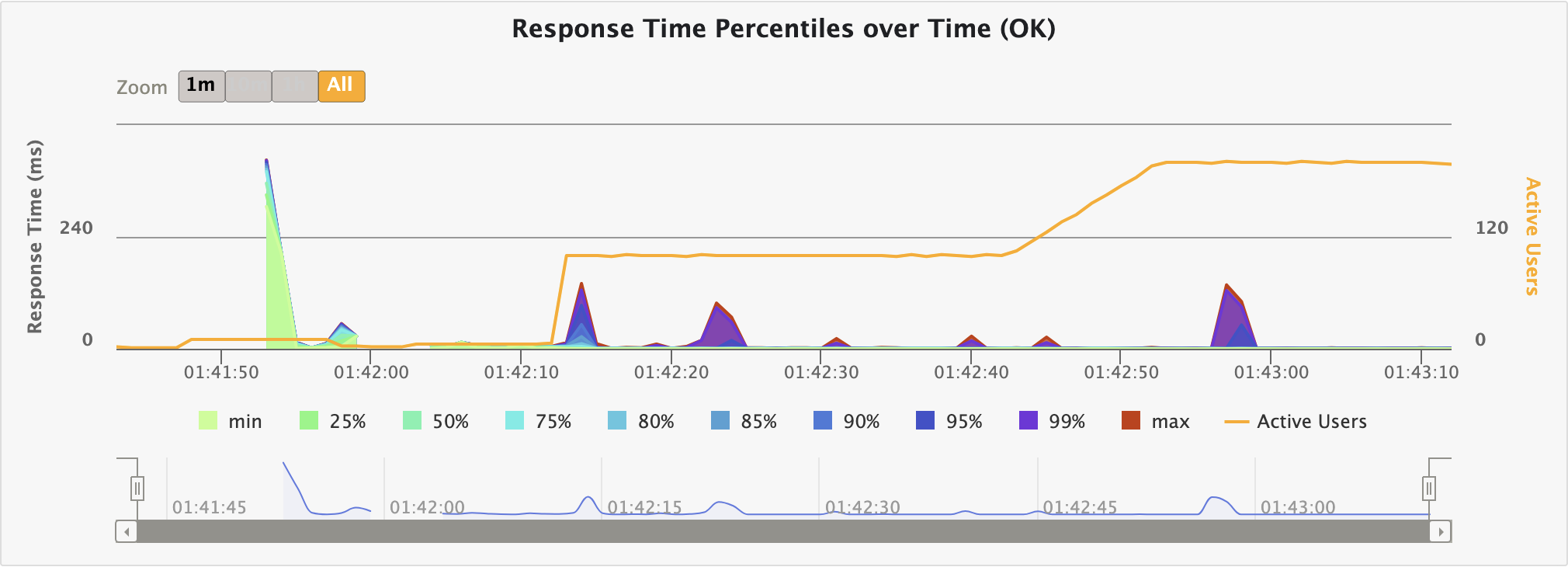
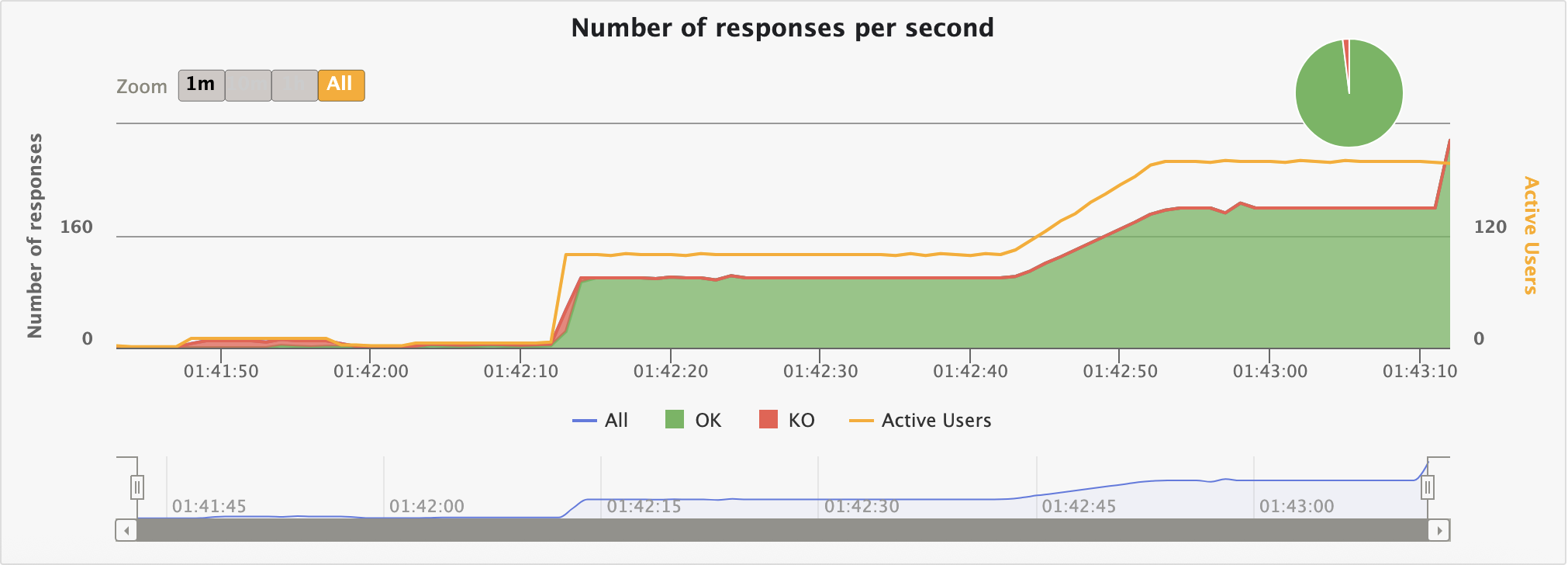
테스트는 약 1분 30초 정도 소요되었다. 위 사진은 nio + VT 조합의 그래프다. (모든 조합에 대한 그래프까지는 필요없을거 같아서 걍 인증용)
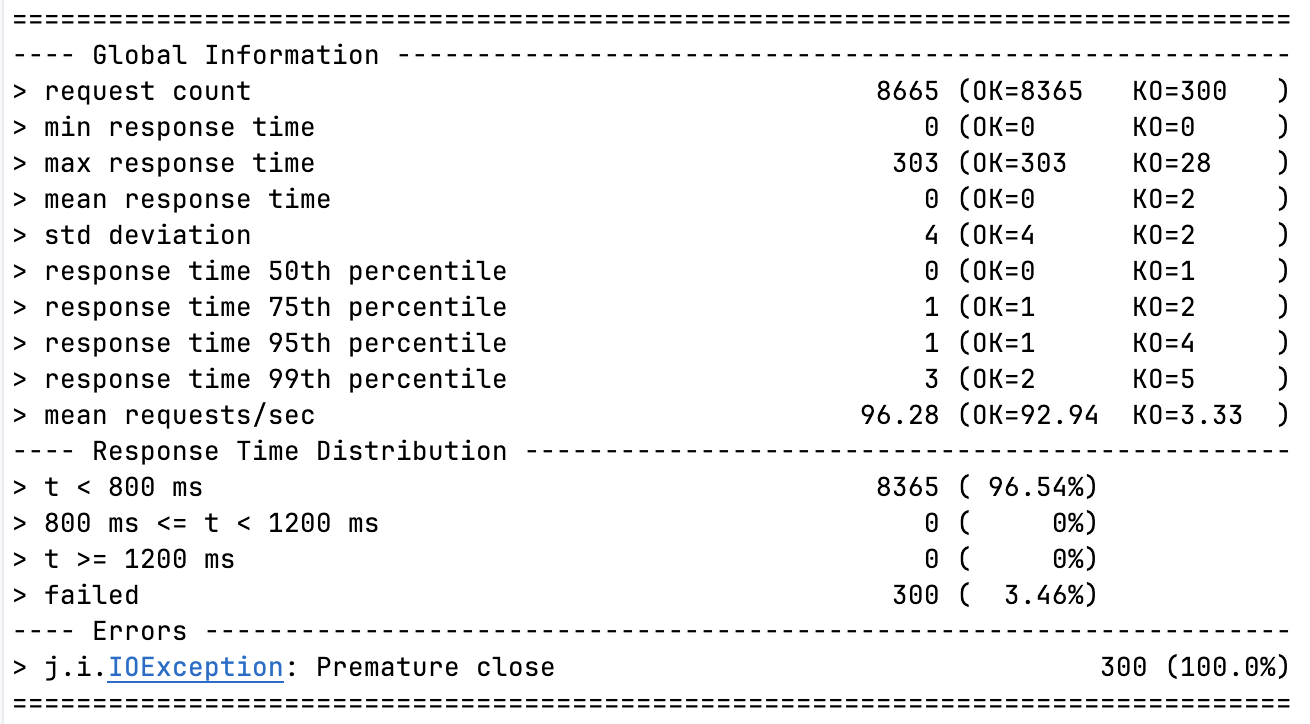
Hybrid + Platform
Hybrid + Virtual
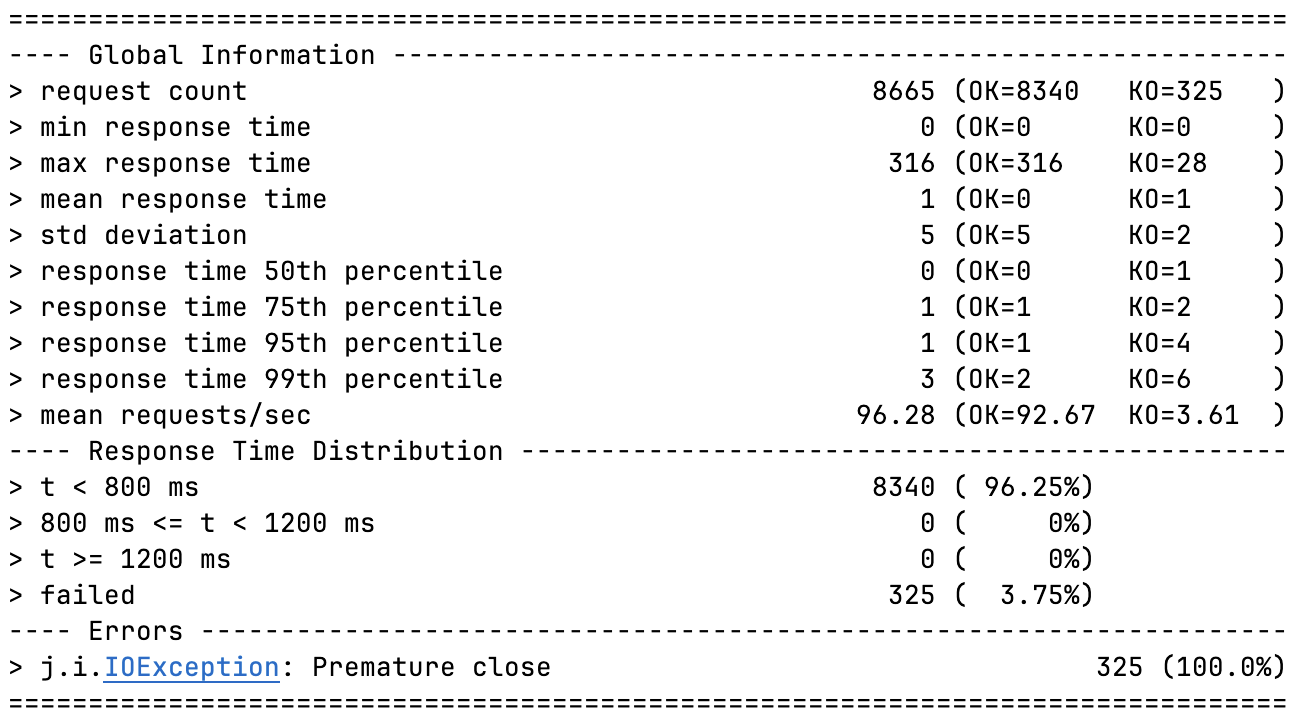
NIO + Platform
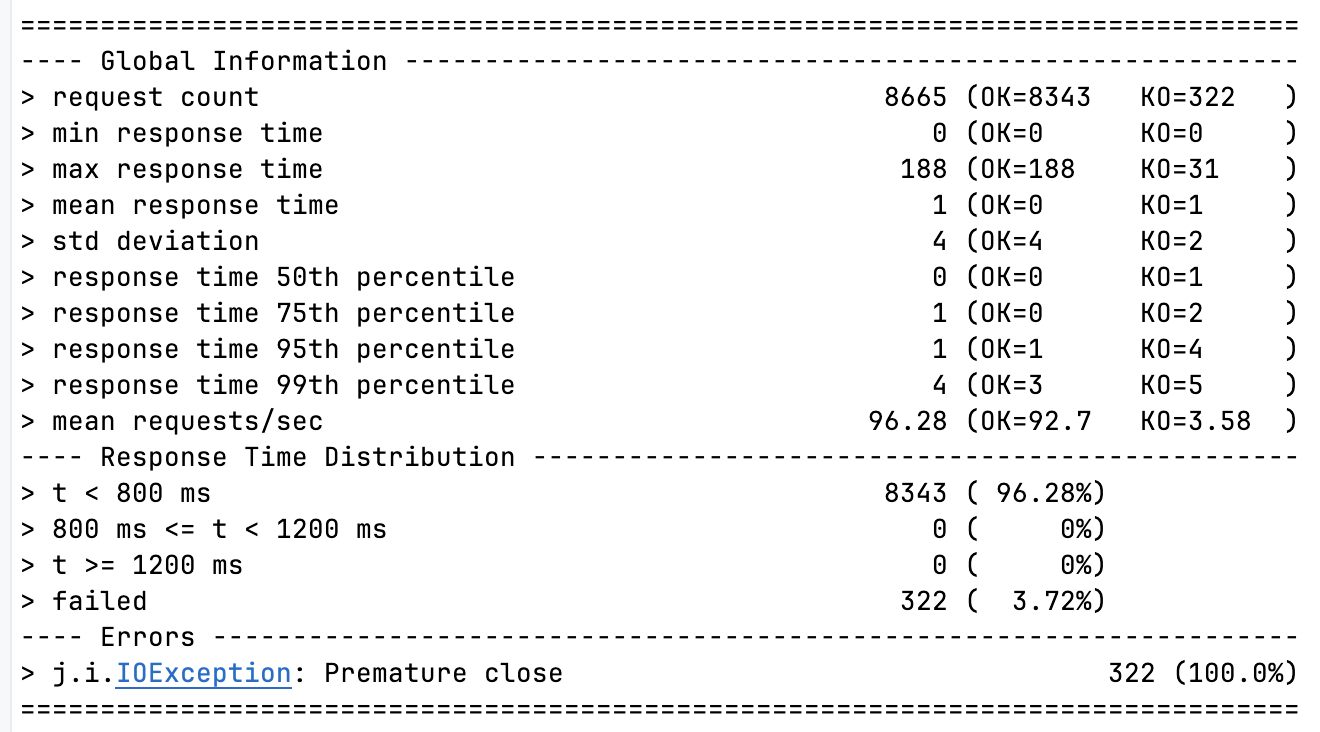
NIO + Virtual
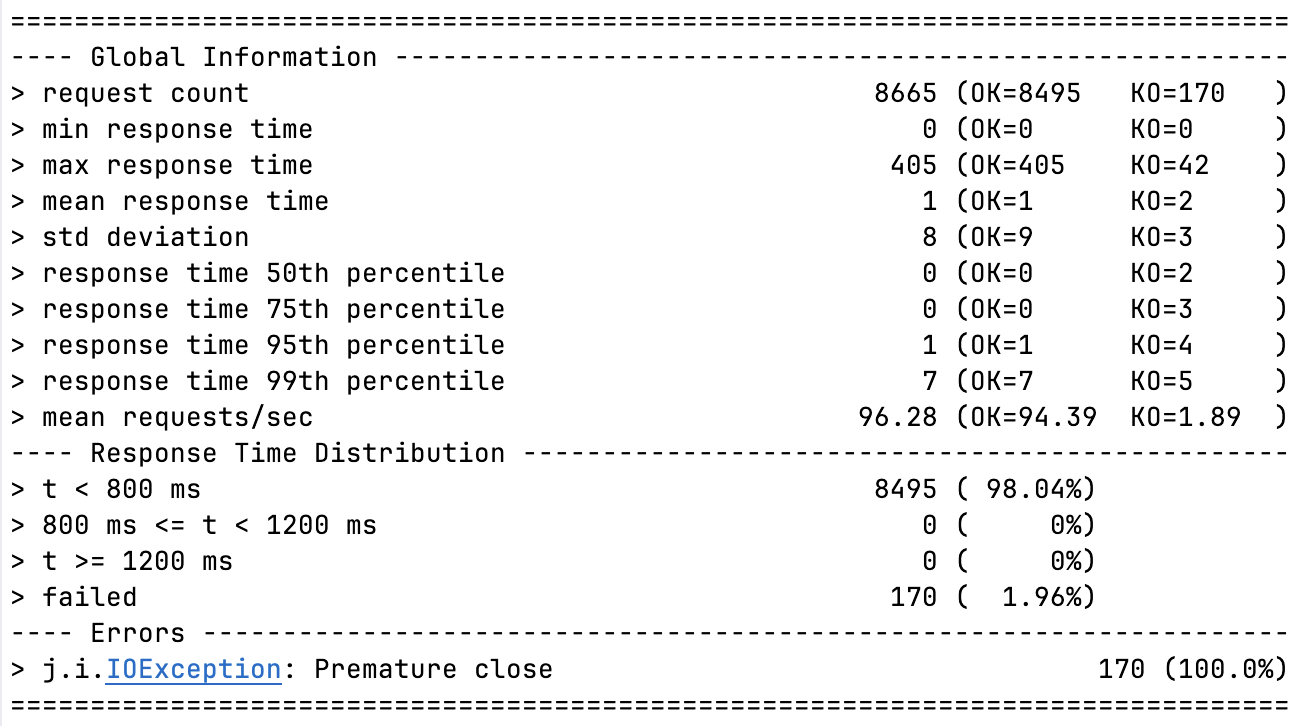
전체 서버 성능 개선 요약
| I/O 모델 | Executor 타입 | 워밍업 상태 | 기존 성공률(%) | 개선 후 성공률(%) | 개선폭(Δ%) | 비고 |
|---|---|---|---|---|---|---|
| Hybrid (BIO+NIO) | Virtual Threads | ✅ Full Warm-up | 99.73 | 99.84 | +0.11 | |
| NIO | Virtual Threads | ✅ Full Warm-up | - | 99.8 | - | 이전 측정치 없음 |
| Hybrid (BIO+NIO) | Platform Threads | ⚠️ Partial Warm-up | 83.95 | 96.54 | +12.59 | BIO fallback 감소 |
| Hybrid (BIO+NIO) | Virtual Threads | ⚠️ Partial Warm-up | 88.00 | 96.25 | +8.25 | VT에서도 유의미한 개선 |
| NIO | Platform Threads | ⚠️ Partial Warm-up | 72.79 | 96.28 | +23.49 | 셀렉터 경로 워밍업 민감 |
| NIO | Virtual Threads | ⚠️ Partial Warm-up | 69.00 | 98.00 | +29.00 | cold-start에서 최고 개선 |
전체 서버 성능 개선 분석
이번 리팩토링은 I/O 처리 경로와 스레드 모델별 JIT 워밍업 효과를 체계적으로 검증한 결과, 모든 조합에서 성능이 안정화되었으며, 특히 NIO 기반 구조에서 두드러진 개선이 확인되었다.
Full Warm-up 구간 — 안정성 상한선 검증
정확히는, Full Warm-up 이 아니라, 요청수가 많아서 초반 요청이 덜 실패하기 때문에, 실패에 대한 비율이 낮게 나올 수밖에없다. 실제로 안정화된다면 기존 모델들도 전부 KO를 단 한건도 내지 않았음
| 구분 | 결과 | 해석 |
|---|---|---|
| Hybrid + Virtual Threads | 99.84% (Δ +0.11%) | 이미 안정 상태였던 BIO 루틴과 VT 스케줄링이 조합된 구조로, 변화 폭은 작지만 최종 안정성 최고 수준. |
| NIO + Virtual Threads | 99.8% (기존 미측정) | 완전 워밍업 시 cold path가 완전히 제거됨. selector 루프와 VT 컨텍스트 스위칭이 모두 최적화되어 거의 이론적 상한선 도달. |
완전 워밍업 환경에서는 모든 구조가 99.8% 이상으로 수렴
Partial Warm-up 구간 — 구조별 JIT 민감도 비교
| 구분 | 주요 변화 | 핵심 해석 |
|---|---|---|
| Hybrid + Platform Threads | 83.95 → 96.54 (+12.59%) | BIO fallback 구간의 JIT 타이밍이 개선되어 응답률이 대폭 상승. |
| Hybrid + Virtual Threads | 88.00 → 96.25 (+8.25%) | VT가 스케줄링 부담을 줄이지만, fallback 경로가 남아 있어 개선폭은 제한적. |
| NIO + Platform Threads | 72.79 → 96.28 (+23.49%) | 워밍업 부족 시 가장 민감하게 반응. JIT 컴파일 완료 이후 성능 급상승. |
| NIO + Virtual Threads | 69.00 → 98.00 (+29.00%) | cold-start 환경에서 가장 큰 폭의 개선. 가상 스레드의 경량 context switch가 JIT 안정화 이후 폭발적 효율로 전환. |
-
Hybrid 구조는 JIT 개선 효과가 중간 정도로 제한됨 — 이미 안정화 비율이 높았던 것이 원인인 듯 하다.
-
NIO 구조는 워밍업 유무에 따라 성능이 극적으로 변하며, 특히 Virtual Thread 조합이 가장 큰 JIT 민감도를 가짐을 확인할 수 있었다.
전체 경향
| 항목 | 요약 |
|---|---|
| JIT 워밍업 효과 | 요청 약 300건 이후 성능이 포화 상태에 도달하며, 이후 안정적으로 99% 이상 유지됨. |
| 스레드 모델 영향 | Virtual Thread 조합은 cold-start에 취약하지만, 워밍업 이후 효율성은 가장 뛰어남. |
| I/O 경로 차이 | NIO 계열이 JIT 및 캐시 친화적이며, Hybrid는 안정성 면에서 절충적. |
| GC/메모리 | 리팩토링 이후 Eden 압력이 약간 증가했으나 전체 pause time은 안정적. |
결론
-
Partial → Full Warm-up 전환만으로 최대 +29% 향상이 가능함을 실증.
-
NIO + Virtual Thread 조합은 JIT 컴파일 안정화 이후 사실상 최적 구조로 확인됨
-
Gatling 리포트에서 현재 1500 rps까진 처리 가능 확인 (그 이상에선 검증 안해봄)
-
전체적으로 Sprout 서버는 리팩토링 이후 처리율, 안정성, 지연 편차 모두 개선되었으며, 더미 요청(약 300건)만 선행하면 실운영 환경에서도 100%에 근접한 응답 성공률이 예상됨.
-
평균 응답시간 0ms, P95 1ms, P99 1ms